Hello geeks! Yes, I’m back with yet another post on the Azure OpenAI Service. There always seems to be more cool stuff to talk about with this service that isn’t specific to the models themselves. If you follow this blog, you know I’ve spent the past year examining the operational and security aspects of the service. Through trial and error and a ton of discussions with S500 customers across all industries, I’ve learned a ton and my goal has to be share back those lessons learned with the wider community. Today I bring you more nuggets of useful information.
Like any good technology nerd, I’m really nosey. Over the years I’ve learned about all the interesting information web-based services return the response headers and how useful this information can be to centrally capture and correlate to other pieces of logging information. These headers could include things like latency, throttling information, or even usage information that can be used to correlate the costs of your usage of the service. While I had glanced at the response headers from the Azure OpenAI Service when I was doing my work on the granular chargeback and streaming ChatCompletions posts, I hadn’t gone through the headers meticulously. Recently, I was beefing up Shaun Callighan’s excellent logging helper solution with some additional functionality I looked more deeply at the headers and found some cool stuff that was worth sharing.
How to look at the headers (skip if you don’t want to nerd out a bit)
My first go to whenever examining a web service is to power up Fiddler and drop it in between my session and the web service. While this works great on a Windows or MacOS box when you can lazily drop the Fiddler-generated root CA (certificate authority) into whatever certificate store your browser is using to draw its trusted CAs from, it’s a bit more work when conversing with a web service through something like Python. Most SDKs in my experience use the requests module under the hood. In that case it’s a simple matter of passing a kwarg some variant of the option to disable certificate verification in the requests module (usually something like verify=false) like seen below in the azure.identity SDK.
Interestingly, the Python openai SDK does not allow for this. Certificate verification cannot be disabled with an override. Great security control from the SDK developers, but no thought of us lazy folks. The openai SDK uses httpx under the hood, so I took the nuclear option and disabled verification of certificates in the module itself. Obviously a dumb way of doing it, but hey lazy people gotta lazy. If you want to use Fiddler, be smarter than me and use one of the methods outlined in this post to trust the root CA generated by Fiddler.
All this to get the headers? Well, because I like you, I’m going to show you a far easier way to look at these headers using the native openai SDK.
The openai SDK doesn’t give you back the headers by default. Instead the response body is parsed neatly for you and a new object is returned. Thankfully, the developers of the library put in a way to get the raw response object back which includes the headers. Instead of using the method chat.completions.create you can use chat.completions.with_raw_response.create. Glancing at the SDK, it seems like all methods supported by both the native client and AzureOpenAI client support the with_raw_response method.
Using this alternative method will save you from having to mess with the trusted certificates as long as you’re good with working with a text-based output like the below.
This can be incredibly useful if you’re dropped some type of gateway, such as an APIM (API Management) instance in front of the OpenAI instance for load balancing, authorization, logging, throttling etc. If you’re using APIM, you can my buddy Shaun’s excellent APIM Policy Snippet to troubleshoot a failing APIM policy. Now that I’ve given you a workaround to using Fiddler, I’m going to use Fiddler to explore these headers for the rest of the post because I’m lazy and I like a pretty GUI sometimes.
Examining the response headers and correlating data to diagnostic logs
Here we can see the response headers returned from a direct call to the Azure OpenAI Service.
The headers which should be of interest to you are the x-ms-region, x-ratelimit-remaining-requests, x-ratelimit-remaining-tokens, and x-request-id. The x-ms-region is the region where the Azure OpenAI instance you called is located (I’ll explain why this can be useful in a bit). The x-ratelimit headers tell you how close you are to hitting rate limits on a specific instance of a model in an AOAI instance. This is where load balancing and provisioned throughput units can help mitigate the risk of throttling. The load balancing headers are still important to your application devs to pay attention to and account for even if you’re load balancing across multiple instances because load balancing mitigates but doesn’t eliminate the risk of throttling. The final interesting header is the apim-request-id which is the unique identifier of this specific request to the AOAI service. If you’re wondering, yes it looks like the product group has placed the compute running the models behind an instance of Azure API Management.
Let’s first start with the apim-request-id response header. This header is useful because it can be used to correlate a specific request it’s relevant entry in the native diagnostic logging for the Azure OpenAI Service. While I’ve covered the limited use of the diagnostic logging within the service, there are some good nuggets in there which I’ll cover now.
Using the apim-request-id, I can make a query to wherever I’m storing the diagnostic logs for the AOAI instance to pull the record for the specific request. In my example I’m using a Log Analytics Workspace. Below you can see my Kusto query which pulls the relevant record from the RequestResponse category of logs.
Correlating a request to the Azure OpenAI Service to the diagnostic logs
There are a few useful pieces of information in this log entry.
DurationMs – This field tells us how long the response took from the Azure OpenAI Service. My favorite use of this field comes when considering non-PTU-based Azure OpenAI instances. Lots of people want to use the service and the underlining models in a standard pay-as-you-go tier can get busy in certain regions at certain times. If you combine this information with the x-ms-region response header you can begin to build a picture of average response times per region at specific times of the day. If you’re load balancing, you can tweak your logic to direct your organization’s prompts to the region that has the lowest response time. Cool right?
properties_s.streamType – This field tells you whether or not the request was a streaming-type completion. This can be helpful to give you an idea of how heavily used streaming is in your org. As I’ve covered previously, capturing streaming prompts and completions and calculating token usage can a challenge. This property can help give you an idea how heavily used it is across your org which may drive you to get a solution in place to do that calculation sooner rather than later.
properties_s.modelName, modelVersion – More useful information to enrich the full picture of the service usage while being able to trace that information back to specific prompts and responses.
objectId – If your developers are using Entra ID-based identities to authenticate to the AOAI service (which you should be doing and avoiding use of API keys where possible), you’ll have the objectid of the specific service principal that made the request.
Awesome things you can do with this information
You are likely beginning to see the value of collecting the response headers, prompt and completions from the request and respond body, and enriching that information from logging data collected from diagnostics logs. With that information you can begin getting a full picture of how the service is being used across your organization.
Examples include:
Calculating token usage for organizational chargebacks
Optimizing the way you load balance to take advantage of less-used regions for faster response times
Making troubleshooting easier by being able to trace a specific response back to which instance it, the latency, and the prompt and completion returned by the API.
There are a ton of amazing things you can do with this data.
How the hell do you centrally collect and visualize this data?
Your first step should be to centrally capturing this data. You can use the APIM pattern that is quite popular or you can build your own solution (I like to refer to this middle tier component as a “Generative AI Gateway”. $50 says that’s the new buzzwords soon enough). Either way, you want this data captured and delivered somewhere. In my demo environment I deliver the data to an Event Hub, do a bit of transformation and dump it into a CosmosDB with Stream Analytics, and the visualize it with PowerBI. An example of the flow I use in my environment is below.
Example flow of how to capture and monetize operational and security data from your Azure OpenAI Usage
The possibilities for the architecture are plentiful, but the value of this data to operations, security, and finance is worth the effort to assemble something in your environment. I hope this post helped to get your more curious about what your usage looks like and how could use this data to optimize operationally, financially, and even throw in a bit more security with more insight into what your users are doing with this GenAI models by reviewing the captured prompts and responses. While there isn’t a lot of regulation around the use of GenAI yet, it’s coming and by capturing this information you’ll be ready to tackle it.
Welcome back folks! I recently had a few customers ask me about using certificates with Azure Key Vault and switching from using a client secret to a client certificate for their Azure AD (Active Directory) service principals. The questions put me on a path of diving deeper around the topics which results in some great learning and opportunity to create some Python code samples.
Azure Key Vault is Microsoft’s solution for secure secret, key, and credential management. If you’re coming from the AWS (Amazon Web Services) realm, you can think of it as AWS KMS (Key Management Services) with a little bit of AWS Secrets Manager and AWS Certificate Manager thrown in there. The use cases for secrets and keys are fairly well known and straightforward, so I’m going instead focus time on the certificates use case.
In a world where passwordless is the newest buzzword, there is an increasing usage of secrets (or passwords) in the non-human world. These secrets are often used to programmatically interact with APIs. In the Microsoft world you have your service principals and client secrets, in the AWS world you have your IAM Users with secret access keys, and many more third-parties out there require similar patterns that require the use of an access key. Vendors like Microsoft and AWS have worked to mitigate this growing problem in the scope of their APIs by introducing features such as Azure Managed Identities and AWS IAM Roles which use short lived dynamic secrets. However, both of these solutions work only if your workload is running within the relevant public cloud and the service it’s running within supports the feature. What about third-party APIs, multi-cloud workloads, or on-premises workloads? In those instances you’re many of times forced to fall back to the secret keys.
There is a better option to secret keys, and that is client certificates. While a secret falls into the “something you know” category, client certificates fall into the “something you have” category. They provide an higher assurance of identity (assuming you exercise good key management practices) and can have more flexibility in their secure storage and usage. Azure Service Principals support certificate-based authentication in addition to client secrets and Azure Key Vault supports the secure storage certificates. Used in combination, it can yield some pretty cool patterns.
Before I get into those patterns, I want to cover some of the basics in how Azure Key Vault stores certificates. There are some nuances to how it’s designed that is incredibly useful to understand. I’m not going to provide a deep dive on the inner workings of Key Vault, the public documentation does a decent enough job of that, but I am going to cover some of the basics which will help get you up and running.
Certificates can be both imported into and generated within Azure Key Vault. These certificates generated can be self-signed, generated from a selection of public CAs (certificate authorities) it is integrated with, or can be used to generate a CSR (certificate signing request) you can full-fill with your own CA. These processes are well detailed in the documentation, so I won’t be touching further on them.
Once you’ve imported or generated a certificate and private key into Key Vault, we get into the interesting stuff. The components of the certificate and private key are exposed in different ways through different interfaces as seen below.
Key Vault and certificates
Metadata about the certificate and the certificate itself are accessible via the certificates interface. This information includes the certificate itself provided in DER (distinguished encoded rules) format, properties of the certificate such as the expiration date, and metadata about the private key. You’ll use this interface to get a copy of the certificate (minus private key) or pull specific properties of the certificate such as the thumbprint.
Operations using the private key such as sign, verify, encrypt, and decrypt, are made available through the key interface. Say you want to sign a JWT (JSON Web Token) to authenticate to an API, you would use this interface.
Lastly, the private key is available through the secret interface. This is where you could retrieve the private key in PEM (privacy enhanced mail) or PKCS#12 (public key cryptography standards) format if you’ve set the private key to be exportable. Maybe you’re using a library like MSAL (Microsoft Authentication Library) which requires the private key as an input when obtaining an OAuth access token using a confidential client.
Now that you understand those basics, let’s look at some patterns that you could leverage.
In the first pattern consider that you have a CI/CD (continuous integration / continuous delivery) running on-premises that you wish to use to provision resources in Azure. You have a strict requirement from your security team that the infrastructure remain on-premises. In this scenario you could provision a service principal that is configured for certificate authentication and use the MSAL libraries to authenticate to Azure AD to obtain the access tokens needed to access the ARM API (Azure Resource Manager). Here is Python sample code demonstrating this pattern.
On-premises certificate authentication with MSAL
In the next pattern let’s consider you have a workload running in the Azure AD tenant you dedicate to internal enterprise workloads. You have a separate Azure AD tenant used for customer workloads. Within an Azure subscription associated with the customer tenant, there is an instance of Azure Event Hub you need to access from a workload running in the enterprise tenant. For this scenario you could use a pattern where the workload running in the enterprise tenant uses an Azure Managed Identity to retrieve a client certificate and private key from Key Vault to use with the MSAL library to obtain an access token for a service principal in the customer tenant which it will use to access the Event Hub.
For the last pattern, let’s consider you have the same use case as above, but you are using the Premium SKU of Azure Key Vault because you have a regulatory requirement that the private key never leaves the HSM (hardware security module) and all cryptographic operations are performed on the HSM. This takes MSAL out of the picture because MSAL requires the private key be provided as a variable when using a client certificate for authentication of the OAuth client. In this scenario you can use the key interface of Key Vault to sign the JWT used to obtain the access token from Azure AD. This same pattern could be leveraged for other third-party APIs that support certificate-based authentication.
Well folks I’m going to keep it short and sweet. Hopefully this brief blog post has helped to show you the value of Key Vault and provide some options to you for moving away from secret-based credentials for your non-human access to APIs. Additionally, I really hope you get some value out of the Python code samples. I know there is a fairly significant gap in Python sample code for these types of operations, so hopefully this begins filling it.
I’ve recently had a number of inquiries on Microsoft’s AAD (Azure Active Directory) B2C (Business-To-Consumer) offering. For those infrastructure folks who have had to manage customer identities in the past, you know the pain of managing these identities with legacy solutions such as LDAP (Lighweight Directory Access Protocol) servers or even a collection of Windows AD (Active Directory) forests. Developers have suffered along with us carrying the burden of securely implementing the technologies into their code.
AAD B2C exists to make the process easier by providing a modern IDaaS (identity-as-a-service) offering complete with a modern directory accessible over a Restful API, support for modern authentication and authorization protocols such as SAML, Open ID Connect, and OAuth, advanced features such as step-up authentication, and a ton of other bells and whistles. Along with these features, Microsoft also provides a great library in the form of the Microsoft Authentication Library (MSAL).
It had been just about 4 years since I last experimented with AAD B2C, so I was due for a refresher. Like many people, I learn best from reading and doing. For the doing step I needed an application I could experiment with. My first stop was the samples Microsoft provides. The Python pickings are very slim. There is a basic web application Ray Lou put together which does a great job demonstrating basic authentication. However, I wanted to test additional features like step-up authentication and securing a custom-built API with AAD B2C so I decided to build on top of Ray’s solution.
I began my journey to create the web app and web API I’ll be walking through setting up with this post. Over the past few weeks I spent time diving into the Flask web framework and putting my subpar Python skills to work. After many late nights and long weekends spent reading documentation and troubleshooting with Fiddler, I finished the solution which costs of a web app and web API.
The solution is quite simple . It is intended to simulate a scenario where a financial services institution is providing a customer access the customer’s insurance policy information . The customer accesses a web frontend (python-b2c-web) which makes calls to a API (python-b2c-api) which then retrieves policy information from an accounts database (in this case a simple JSON file). The customer can use the self-service provisioning capability of Azure B2C to create an account with the insurance company, view their policy, and manage the beneficiary on the policy.
AAD B2C provides the authentication to the web front end (python-b2c-web) via Open ID Connect. Access to the user’s policy information is handled through the API (python-b2c-api) using OAuth. The python-b2c-web frontend uses OAuth to obtain an access token which is uses for delegated access to python-b2c-api to retrieve the user’s policy information. The claims included in the access token instruct the python-b2c-api which record to pull. If the user wishes to change the beneficiary on the policy, the user is prompted for step-up authentication requiring an MFA authentication.
The solution uses four Azure AD B2C UserFlows. It has a profile editing user flow which allows the user to change information stored in the AAD B2C directory about the user such as their name. A password reset flow allows the user to change the password for their local AAD B2C identity. Two sign-up/sign-in flows exist one with no MFA and one with MFA enforced and two sign-up / sign-in flows. The non-MFA enabled flow is the kicked off at login to python-b2c-web while the MFA enabled flow is used when the user attempts to change the beneficiary.
With the basics on the solution explained, let’s jump in to how to set it up. Keep in mind I’ll be referring to public documentation where it makes sense to avoid reinventing the wheel. At this I’m providing instructions as to how to run the code directly on your machine and additionally instructions for running it using Docker. Before we jump into how to get the code up and running, I’m going to walkthrough setting up Azure AD B2C.
Setting up Azure AD B2C
Before you go setting up Azure AD B2C, you’ll need a valid Azure AD Tenant and Azure Subscription. You can setup a free Azure account here. You will need at least contributor within the Azure Subscription you plan on using to contain the Azure AD B2C directory.
Follow the official documentation to setup your Azure B2C directory once you have your Azure Subscription setup and ready to go. Take note of the name of the single-label DNS name you use for your Azure B2C directory. This will be the unique name you set that prefixes .onmicrosoft.com (such as myb2c.onmicrosoft.com).
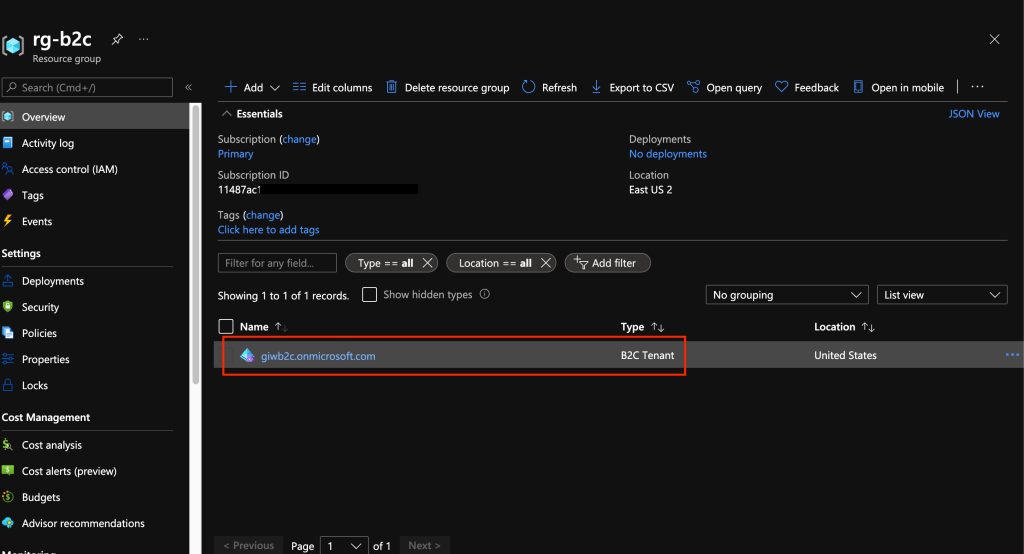
Creation of the Azure AD B2C directory will create a resource of type B2C Tenant in the resource group in the Azure Subscription you are using.
In addition to the single-label DNS name, you’ll also need the note down tenant ID assigned to the B2C directory for use in later steps. You can obtain the tenant ID by looking at the B2C Tenant resource in the Azure Portal. Make sure you’re in the Azure AD directory the Azure Subscription is associated with.
Screenshot of Azure AD B2C resource in Azure Resource Group
If you select this resource you’ll see some basic information about your B2C directory such as the name and tenant ID.
Screenshot of Overview of an Azure AD Tenant resource
Once that is complete the next step is to register the web front end (python-b2c-web) and API (python-b2c-api). The process of registering the applications establishes identities, credentials, and authorization information the applications use to communicate with Azure B2C and each other. This is a step where things can get a bit confusing because when administering an Azure AD B2C directory you need to switch authentication contexts to be within the directory. You can do this by selecting your username in the top right-hand corner of the Azure Portal and selecting the Switch Directory link.
Screenshot of how to switch between Azure AD and Azure AD B2C directories
This will bring up a list of the directories your identity is authorized to access. In the screenshot below you’ll see my Azure AD B2C directory giwb2c.onmicrosoft.com is listed as an available directory. Selecting the directory will be me in the context of the B2C directory where I can then register applications and administer other aspects of the B2C directory.
Screenshot showing available directories
Once you’ve switched to the Azure AD B2C directory context you can search for Azure B2C in the Azure search bar and you’ll be able to fully administer the B2C directory. Select the App Registrations link to begin registering the python-b2c-web application.
Screenshot of Azure AD B2C administration options
In the next screen you’ll be see the applications currently registered with the B2C directory. Click the New registration button to begin a new registration.
In the Register an application screen you need to provide information about the application you are registering. You can name the application whatever you’d like as this is used as the display name when viewing registered applications. Leave the Who can use this application or access thisAPI set the Accountsin any identity provider or organizational directory (for authenticating users with user flows). Populate the Redirect URI with URI Azure B2C should redirect the user’s browser to after the user has authenticate. This needs to be an endpoint capable of processing the response from Azure AD B2C after the user has authenticated. For this demonstration application you can populate the URI with http://localhost:5000/getAToken. Within the application this URI will process the authorization code returned from B2C and use it to obtain the ID token of the user. Note that if you want to run this application in App Services or something similar you’ll need to adjust this value to whatever DNS name your application is using within that service.
Leave the Grant admin consent to openid and offline_access permissions option checked since the application requires permission to obtain an id token for user authentication to the application. Once complete hit the Register button. This process creates an identity for the application in the B2C directory and authorizes it to obtain ID tokens and access tokens from B2C.
Screenshot showing how to register the python-b2c-web application
Now that the python-b2c-web application is registered, you need to obtain some information about the application. Go back to the main menu for the B2C Directory, back into the App Registrations and select the newly registered application. On this page you’ll have the ability to administer a number of aspects of the application such as creating credentials for the application to support confidential client flows such as the authorization code flow which this application uses.
Before you do any configuration, take note of the Application (client) ID. You’ll ned this for later steps.
Screenshot of registered application configuration options
The client ID is used to identify the application to the Azure B2C directory, but you still need a credential to authenticate it. For that you’ll go to Certificates & secrets link. Click on the New client secret button to generate a new credential and save this for later.
You will need to register one additional redirect URI. This redirect URI is used when the user authenticates with MFA during the step-up process. Go back to the Overview and click on the Redirect URIs menu item on the top section as seen below.
Screenshot of overview menu and Redirect URIs link
Once the new page loads, add a redirect URI which is found under the web section. The URI you will need to add is http://localhost:5000/getATokenMFA. Save your changes by hitting the Save button. Again, note you will need to adjust this URI if you deploy this into a service such as App Services.
At this point the python-b2c-web (or web frontend) is registered, but you need to now register python-b2c-api (the API). Repeat the steps above to register the python-b2c-api. You’ll select the same except you do not need to provide a redirect URI since the API won’t be directly authenticating the user.
Once the python-b2c-api is registered, go into the application configuration via the App Registrations menu and record the Application (client) ID as you’ll use this to configuration the application later on. After you’ve recorded that information select the Expose anAPI link. Here you will register the two OAuth scopes I’ve configured in the application. These scopes will be included in the access token obtained by python-b2c-web when it makes calls to python-b2c-api to get policy information for the user.
Select the Add a scopebutton and you’ll be prompted to set an Application ID URI which you need to set to api. Once you’ve set it, hit the Save and continue button.
Screenshot of setting the Application ID URI for the python-b2c-api
The screen will refresh you’ll be able to add your first scope. I have defined two scopes within the pyton-b2c-api. One is called Accounts.Read which grants access to read policy information and one for Accounts.Write which grants access to edit policy information. Create the scope for the Accounts.Read and repeat the process for Accounts.Write.
As a side note, by default B2C grants application registered with it the offline_access and openid permissions for Microsoft Graph. Since python-b2c-api won’t be authenticating the user and will simply be verifying the access token passed by the python-b2c-web, you could remove those permissions if you want. You can do this through theAPI permissions link which is located on the application configuration settings of the python-b2c-api.
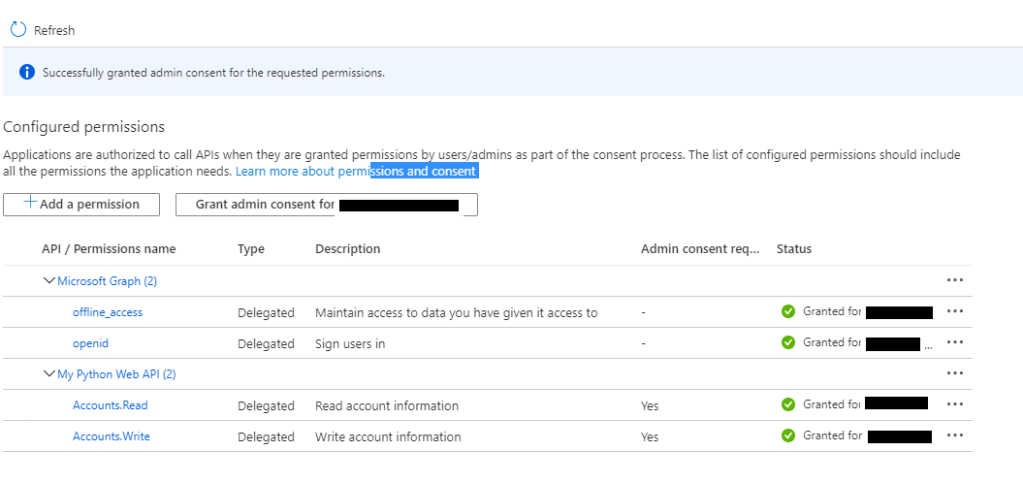
The last step you have in the B2C portion of Azure is to grant the python-b2c-web application permission to request an access token for the Accounts.Read and Accounts.Write scopes used by the python-b2c-api application To do this you need to go back into the application configuration for the python-b2c-web application and go to the API permissions link. Click the Add a permission link. In the Request API permissions window, select My APIs link and select the python-b2c-api application you registered. Select the two permissions (Accounts.Read and Accounts.Write) and click the Add permissions link.
Screenshot of granting permissions to the python-b2c-web application
To finish up with the permissions piece you’ll grant admin consent to permissions. At the API permissions window, click the Grant admin consent for YOUR_TENANT_NAME button.
Screenshot of granting admin consent to the new permissions
At this point we’ve registered the python-b2c-web and python-b2c-api applications with Azure B2C. We now need to enable some user flows. Azure B2C has an insanely powerful policy framework that powers the behavior of B2C behind the scenes that allow you to do pretty much whatever you can think of. With power comes complexity, so expect to engage professional services if you want to go to the custom policy route. Azure AD B2C also comes with predefined user flows that provide for common user journeys and experiences. Exhaust your ability to use before you go the custom policy route.
For this solution you’ll be using predefined user flows. You will need to create four predefined user flows named exactly as outlined below. You can use the instructions located here for creation of the user flows. When creating the sign-in and sign-up flows (both MFA and non-MFA) make sure to configure the user attributes and application claims to include the Display Name, Email Address, Given Name, and Surname attributes at a minimum. The solution will be expecting these claims and be using them throughout the application. You are free to include additional user attributes and claims if you wish.
Screenshot of user flows that must be created
At this point you’ve done everything you need to to configure Azure B2C. As a reminder make sure you’ve collected the Azure AD B2C single-label DNS name, Azure AD B2C Tenant ID, python-b2c-web application (client) ID and client secret, and python-b2c-api application (client) ID.
In the next section we’ll setup the solution where the code will run directly on your machine.
(Option 1) Running the code directly on your machine
With this option you’ll run the Python code directly on your machine. For prerequisites you’ll need to download and install Visual Studio Code and Python 3.x.
The python-b2c-web folder contains the web front end application and the python-b2c-api contains the API application. The accounts.json file in the python-b2c-api folder acts as the database containing the policy information. If a user does not have a policy, a policy is automatically created for the user by the python-b2c-api application the first time the user tries to look at the policy information. The app_config.py file in the python-b2c-web folder contains all the configuration options used by python-b2c-web application. It populates any key variables with environment variables you will set in a later step. The app.py files in both directories contain the code for each application. Each folder also contains a Dockerfile if you wish to deploy the solution as a set of containers. See the option 2 running as containers sectionfor steps on how to do this.
Once the repo has cloned you’ll want to open two Terminal instances in Visual Studio Code. You can do this with CTRL+SHIFT+` hotkey. In your first terminal navigate python-b2c-web directory and in the second navigate to the python-b2c-api directory.
In each terminal we’ll setup a Python virtual directory to ensure we don’t add a bunch of unneeded libraries into the operating system’s central Python instance.
Run the command in each terminal to create the virtual environments. Depending on your operating system you may use to specify python3 instead of python before the -m venv env. This is because operating systems like Mac OS X come preinstalled with Python2 which will not work for this solution.
python -m venv env
Once the virtual environments will need to activate the virtual environments. On a Windows machine you’ll use the command below. On a Mac this file will be in env/bin/ directory and you’ll need to run the command source env/bin/activate.
env\Scripts\activate
Next, load the required libraries using pip using the command below. Remember to do this for both terminals. If you run into any errors installing the dependencies for python-b2c-web ensure you update the version of pip used in the virtual environment using the command pip install –upgrade pip.
pip install -r requirements.txt
The environments are now ready to go. Next up you need to set some user variables. Within the terminal for the python-b2c-web create variables for the following:
CLIENT_ID – The application (client) id of the python-b2c-web application you recorded.
CLIENT_SECRET – The client secret of the python-b2c-web application you recorded.
B2C_DIR – The single-label DNS name of the B2C directory such as myb2c.
API_ENDPOINT – The URI of the python-b2c-api endpoint which must this to http://localhost:5001 when running the code directly on your machine. If running this solution on another platform such as Azure App Services you’ll need to set this to whatever the URI you’re using for App Services.
Within the terminal for the python-b2c-api create variables for the following:
CLIENT_ID – application (client) id of the python-b2c-api application you recorded earlier
TENANT_ID – tenant ID of the B2C directory you recorded earlier
B2C_DIR – single-label DNS name of the B2C directory such as myb2c
In Windows you can set these variables by using the command below. If using Mac OS X ensure you export the variables after creation after you set them. Remember to set all of these variables. If you miss one the application will fail to run.
set B2C_DIR=myb2c
Now you can start the python-b2c-web web front end application. To do this you’ll use the flask command. In the terminal you setup for the python-b2c-web application, run the following command:
flask run -h localhost -p 5000
Then in the terminal for the python-simple-web-api, run the following command:
flask run -h localhost -p 5001
You’re now ready to test the app! Open up a web browser and go to http://localhost:5000.
Navigate to the testing the application section <INSERT LINK> for instructions on how to test the application.
(Option 2) Running as containers
Included in the repository is the necessary Dockerfiles to build both applications as Docker images to run as containers in your preferred container runtime. I’m working on a Kubernetes deployment and will that in time. For the purposes of this article I’m going to assume you’ve installed Docker on your local machine.
The python-b2c-web folder contains the web front end application and the python-b2c-api contains the API application. The accounts.json file in the python-b2c-api folder acts as the database containing the policy information. If a user does not have a policy, a policy is automatically created for the user by the python-b2c-api application the first time the user tries to look at the policy information. The app_config.py file in the python-b2c-web folder contains all the configuration options used by python-b2c-web application. It populates any key variables with environment variables you will set in a later step. The app.py files in both directories contain the code for each application. Each folder also contains a Dockerfile that you will use to build the images.
Navigate to the python-b2c-web directory and run the following command to build the image.
docker build --tag=python-b2c-web:v1 .
Navigate to the python-b2c-api directory and run the following command to build the image.
docker build --tag=python-b2c-api:v1 .
Since we need the python-b2c-web and python-b2c-api applications to communicate, we’re going to create a custom bridged network. This will provide a network that will allow both containers to communicate, connect to the Internet to contact Azure B2C, and find each other using DNS. Note that you must use a custom bridged network to support the DNS feature as the default bridged network doesn’t support the containers finding each other by name.
docker network create b2c
Now that the images are built and the network is created you are ready to spin up the containers. When spinning up each container you’ll need to pass a series of environment variables to the containers. The environment variables are as follows:
CLIENT_ID – The application (client) id of the python-b2c-web application you recorded.
CLIENT_SECRET – The client secret of the python-b2c-web application you recorded.
B2C_DIR – The single-label DNS name of the B2C directory such as myb2c.
API_ENDPOINT – The URI of the python-b2c-api endpoint. As long as you name the container running the python-b2c-api with the name of python-b2c-api, you do not need to set this variable.
Within the terminal for the python-b2c-api create variables for the following:
CLIENT_ID – application (client) id of the python-b2c-api application you recorded earlier
TENANT_ID – tenant ID of the B2C directory you recorded earlier
B2C_DIR – single-label DNS name of the B2C directory such as myb2c
Start a container instance of the python-b2c-web application using the following command:
Once both containers are created proceed to the Testing the Application section of this post.
Testing the Application
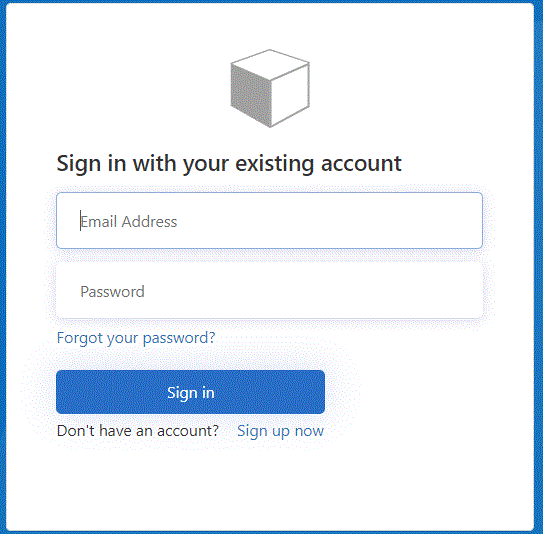
Open a web browser and navigate to http://localhost:5000. The login page below will appear.
Clicking the Sign-In button will open up the B2C sign-in page. Here you can sign-in with an existing B2C account or create a new one. You can also initialize a password reset.
After successfully authenticating you’ll be presented with a simple home page. The Test API link will bring you to the public endpoint of the python-b2c-api application validating that the API is reachable and running. The Edit Profile link will redirect you to the B2C Edit Profile experience. Clicking the My Claims link will display the claims in your ID token as seen below.
Clicking the My Account link causes the python-b2c-web application to request an access token from Azure B2C to access the python-b2c-api and pull the policy information for the user.
Clicking on the Change Beneficiary button will kick off the second MFA-enabled sign-in and sign-up user flow prompting the user for MFA. After successful MFA, the user is redirected to a page where they make the change to the record. Clicking the submit button causes the python-b2c-web application to make a call to the python-b2c-api endpoint modifying the user’s beneficiary on their policy.
That’s about it. Hopefully this helps give you a simple base to mess with Azure AD B2C.
Hi there folks. Recently I was experimenting with the Azure Python SDK when I was writing a solution to pull information about Azure resources within a subscription. A function within the solution was used to pull a list of virtual machines in a given Azure subscription. While writing the function, I recalled that I hadn’t yet had experience handling paged results the Azure REST API which is the underlining API being used by the SDK.
I hopped over to the public documentation to see how the API handles paging. Come to find out the Azure REST API handles paging in a similar way as the Microsoft Graph API by returning a nextLink property which contains a reference used to retrieve the next page of results. The Azure REST API will typically return paged results for operations such as list when the items being returned exceed 1,000 items (note this can vary depending on the method called).
So great, I knew how paging was used. The next question was how the SDK would handle paged results. Would it be my responsibility or would it by handled by the SDK itself?
If you have experience with AWS’s Boto3 SDK for Python (absolutely stellar SDK by the way) and you’ve worked in large environments, you are probably familiar with the paginator subclass. Paginators exist for most of the AWS service classes such as IAM and S3. Here is an example of a code snipped from a solution I wrote to report on aws access keys.
def query_iam_users():
todaydate = (datetime.now()).strftime("%Y-%m-%d")
users = []
client = boto3.client(
'iam'
)
paginator = client.get_paginator('list_users')
response_iterator = paginator.paginate()
for page in response_iterator:
for user in page['Users']:
user_rec = {'loggedDate':todaydate,'username':user['UserName'],'account_number':(parse_arn(user['Arn']))}
users.append(user_rec)
return users
Paginators make handling paged results a breeze and allow for extensive flexibility in controlling how paging is handled by the underlining AWS API.
Circling back to the Azure SDK for Python, my next step was to hop over to the SDK public documentation. Navigating the documentation for the Azure SDK (at least for the Python SDK, I can’ t speak for the other languages) is a bit challenging. There are a ton of excellent code samples, but if you want to get down and dirty and create something new you’re going to have dig around a bit to find what you need. To pull a listing of virtual machines, I would be using the list_all method in VirtualMachinesOperations class. Unfortunately I couldn’t find any reference in the documentation to how paging is handled with the method or class.
So where to now? Well next step was the public Github repo for the SDK. After poking around the repo I located the documentation on the VirtualMachineOperations class. Searching the class definition, I was able to locate the code for the list_all() method. Right at the top of the definition was this comment:
Use the nextLink property in the response to get the next page of virtual
machines.
Sounds like handling paging is on you right? Not so fast. Digging further into the method I came across the function below. It looks like the method is handling paging itself releasing the consumer of the SDK of the overhead of writing additional code.
def internal_paging(next_link=None):
request = prepare_request(next_link)
response = self._client.send(request, stream=False, **operation_config)
if response.status_code not in [200]:
exp = CloudError(response)
exp.request_id = response.headers.get('x-ms-request-id')
raise exp
return response
I wanted to validate the behavior but unfortunately I couldn’t find any documentation on how to control the page size within the Azure REST API. I wasn’t about to create 1,001 virtual machines so instead I decided to use another class and method in the SDK. So what type of service would be a service that would return a hell of a lot of items? Logging of course! This meant using the list method of the ActivityLogsOperations class which is a subclass of the module for Azure Monitor and is used to pull log entries from the Azure Activity Log. Before I experimented with the class, I hopped back over to Github and pulled up the source code for the class. Low and behold we an internal_paging function within the list method that looks very similar to the one for the list_all vms.
def internal_paging(next_link=None):
request = prepare_request(next_link)
response = self._client.send(request, stream=False, **operation_config)
if response.status_code not in [200]:
raise models.ErrorResponseException(self._deserialize, response)
return response
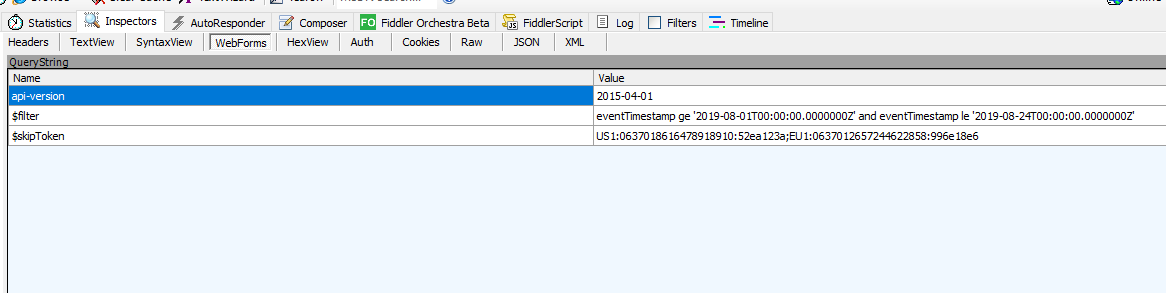
Awesome, so I have a method that will likely create paged results, but how do I validate it is creating paged results and the SDK is handling them? For that I broke out one of my favorite tools Telerik’s Fiddler.
There are plenty of guides on Fiddler out there so I’m going to skip the basics of how to install it and get it running. Since the calls from the SDK are over HTTPS I needed to configure Fiddler to intercept secure web traffic. Once Fiddler was up and running I popped open Visual Studio Code, setup a new workspace, configured a Python virtual environment, and threw together the lines of code below to get the Activity Logs.
from azure.common.credentials import ServicePrincipalCredentials
from azure.mgmt.monitor import MonitorManagementClient
TENANT_ID = 'mytenant.com'
CLIENT = 'XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX'
KEY = 'XXXXXX'
SUBSCRIPTION = 'XXXXXX-XXXX-XXXX-XXXX-XXXXXXXX'
credentials = ServicePrincipalCredentials(
client_id = CLIENT,
secret = KEY,
tenant = TENANT_ID
)
client = MonitorManagementClient(
credentials = credentials,
subscription_id = SUBSCRIPTION
)
log = client.activity_logs.list(
filter="eventTimestamp ge '2019-08-01T00:00:00.0000000Z' and eventTimestamp le '2019-08-24T00:00:00.0000000Z'"
)
for entry in log:
print(entry)
Let me walk through the code quickly. To make the call I used an Azure AD Service Principal I had setup that was granted Reader permissions over the Azure subscription I was querying. After obtaining an access token for the service principal, I setup a MonitorManagementClient that was associated with the Azure subscription and dumped the contents of the Activity Log for the past 20ish days. Finally I incremented through the results to print out each log entry.
When I ran the code in Visual Studio Code an exception was thrown stating there was an certificate verification error.
requests.exceptions.SSLError: HTTPSConnectionPool(host='login.microsoftonline.com', port=443): Max retries exceeded with url: /mytenant.com/oauth2/token (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: unable to get local issuer certificate (_ssl.c:1056)')))
The exception is being thrown by the Python requests module which is being used underneath the covers by the SDK. The module performs certificate validation by default. The reason certificate verification is failing is Fiddler uses a self-signed certificate when configured to intercept secure traffic when its being used as a proxy. This allows it to decrypt secure web traffic sent by the client.
Python doesn’t use the Computer or User Windows certificate store so even after you trust the self-signed certificate created by Fiddler, certificate validation still fails. Like most cross platform solutions it uses its own certificate store which has to be managed separately as described in this Stack Overflow article. You should use the method described in the article for any production level code where you may be running into this error, such as when going through a corporate web proxy.
For the purposes of testing you can also pass the parameter verify with the value of False as seen below. I can’t stress this enough, be smart and do not bypass certificate validation outside of a lab environment scenario.
So this is all well and good when you’re using the requests module directly, but what if you’re using the Azure SDK? To do it within the SDK we have to pass extra parameters called kwargs which the SDK refers to as an Operation config. The additional parameters passed will be passed downstream to the methods such as the methods used by the requests module.
Here I modified the earlier code to tell the requests methods to ignore certificate validation for the calls to obtain the access token and call the list method.
from azure.common.credentials import ServicePrincipalCredentials
from azure.mgmt.monitor import MonitorManagementClient
TENANT_ID = 'mytenant.com'
CLIENT = 'XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX'
KEY = 'XXXXXX'
SUBSCRIPTION = 'XXXXXX-XXXX-XXXX-XXXX-XXXXXXXX'
credentials = ServicePrincipalCredentials(
client_id = CLIENT,
secret = KEY,
tenant = TENANT_ID,
verify = False
)
client = MonitorManagementClient(
credentials = credentials,
subscription_id = SUBSCRIPTION,
verify = False
)
log = client.activity_logs.list(
filter="eventTimestamp ge '2019-08-01T00:00:00.0000000Z' and eventTimestamp le '2019-08-24T00:00:00.0000000Z'",
verify = False
)
for entry in log:
print(entry)
After the modifications the code ran successfully and I was able to verify that the SDK was handling paging for me.
Let’s sum up what we learned:
When using an Azure SDK leverage the Azure REST API reference to better understand the calls the SDK is making
Use Fiddler to analyze and debug issues with the Azure SDK
Never turn off certificate verification in a production environment and instead validate the certificate verification error is legitimate and if so add the certificate to the trusted store
In lab environments, certificate verification can be disabled by passing an additional parameter of verify=False with the SDK method