This is part of my series on GenAI Services in Azure:
- Azure OpenAI Service – Infra and Security Stuff
- Azure OpenAI Service – Authentication
- Azure OpenAI Service – Authorization
- Azure OpenAI Service – Logging
- Azure OpenAI Service – Azure API Management and Entra ID
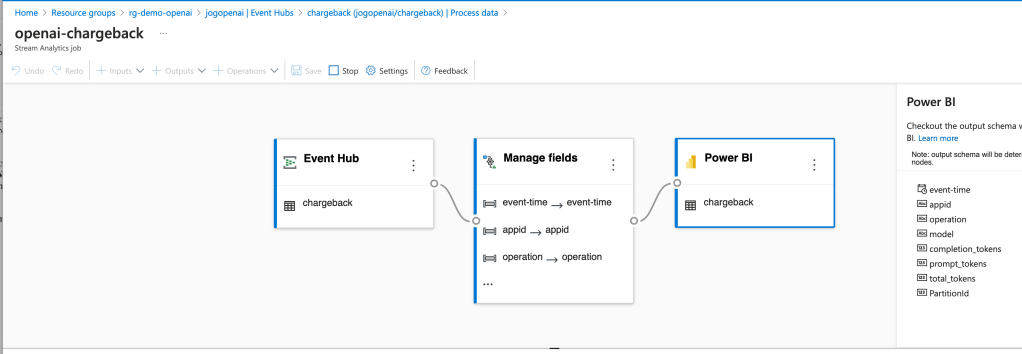
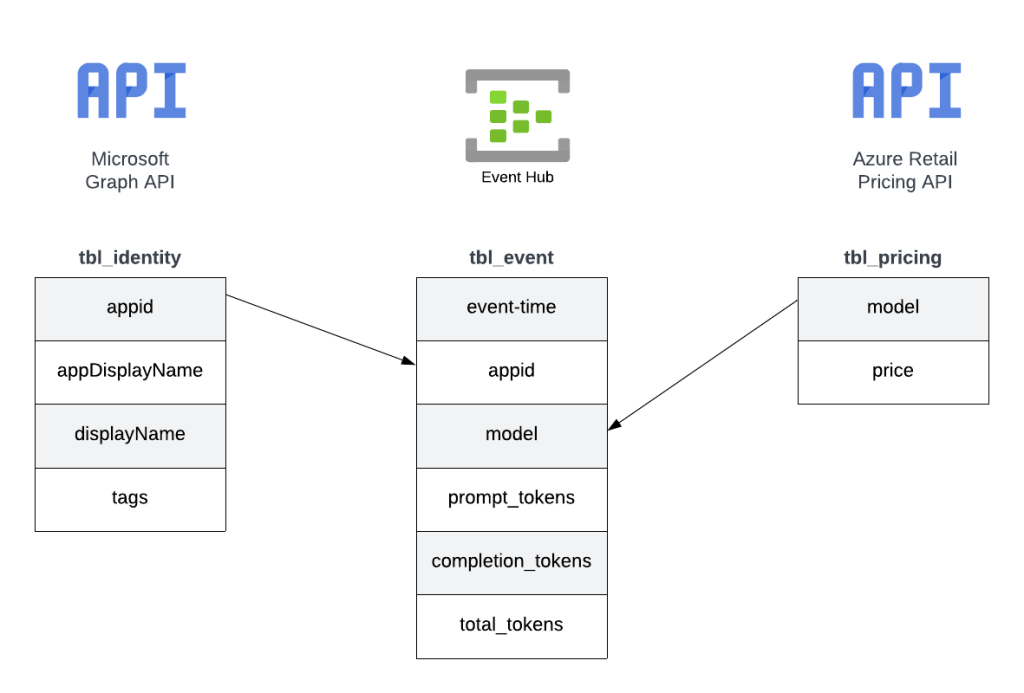
- Azure OpenAI Service – Granular Chargebacks
- Azure OpenAI Service – Load Balancing
- Azure OpenAI Service – Blocking API Key Access
- Azure OpenAI Service – Securing Azure OpenAI Studio
- Azure OpenAI Service – Challenge of Logging Streaming ChatCompletions
- Azure OpenAI Service – How To Get Insights By Collecting Logging Data
- Azure OpenAI Service – How To Handle Rate Limiting
- Azure OpenAI Service – Tracking Token Usage with APIM
- Azure AI Studio – Chat Playground and APIM
- Azure OpenAI Service – Streaming ChatCompletions and Token Consumption Tracking
- Azure OpenAI Service – Load Testing
Updates:
5/23/2024 – Check out my new post on this topic here!
Another Azure OpenAI Service post? Why not? I gotta justify the costs of maintaining the blog somehow!
The demand for the AOAI (Azure OpenAI Service) is absolutely insane. I don’t think I can compare the customer excitement over the service to any other service I’ve seen launch during my time working at cloud providers. With that demand comes the challenge to the cloud service provider of ensuring there is availability of the service for all the customers that want it. In order to do that, Microsoft has placed limits on the number of tokens/minute and requests/minute that can be made to a specific AOAI instance. Many customers are hitting these limits when moving into production. While there is a path for the customer to get the limits raised by putting in a request to their Microsoft account team, this process can take time and there is no guarantee the request can or will be fulfilled.
What can customers do to work around this problem? You need to spin up more AOAI instances. At the time of this writing you can create 3 instances per region per subscription. Creating more instances introduces the new problem distributing traffic across those AOAI instances. There are a few ways you could do this including having the developer code the logic into their application (yuck) ore providing the developer a singular endpoint which is doing the load balancing behind the scenes. The latter solution is where you want to live. Thankfully, this can be done really easily with a piece of Azure infrastructure you are likely already using with AOAI. That piece of infrastructure is APIM (Azure API Management).

As I’ve covered in my posts on AOAI and APIM and my granular chargebacks in AOAI, APIM provides a ton of value the AOIA pattern by providing a gate between the application and the AOAI instance to inspect and action on the request and response. It can be used to enforced Azure AD authentication, provide enhanced security logging, and capture information needed for internal chargebacks. Each of these enhancements is provided through APIM’s custom policy language.

By placing APIM into the mix and using a simple APIM policy we can introduce simple randomized load balancing. Let’s take a deeper look at this policy
<!-- This policy randomly routes (load balances) to one of the two backends -->
<!-- Backend URLs are assumed to be stored in backend-url-1 and backend-url-2 named values (fka properties), but can be provided inline as well -->
<policies>
<inbound>
<base />
<set-variable name="urlId" value="@(new Random(context.RequestId.GetHashCode()).Next(1, 3))" />
<choose>
<when condition="@(context.Variables.GetValueOrDefault<int>("urlId") == 1)">
<set-backend-service base-url="{{backend-url-1}}" />
</when>
<when condition="@(context.Variables.GetValueOrDefault<int>("urlId") == 2)">
<set-backend-service base-url="{{backend-url-2}}" />
</when>
<otherwise>
<!-- Should never happen, but you never know ;) -->
<return-response>
<set-status code="500" reason="InternalServerError" />
<set-header name="Microsoft-Azure-Api-Management-Correlation-Id" exists-action="override">
<value>@{return Guid.NewGuid().ToString();}</value>
</set-header>
<set-body>A gateway-related error occurred while processing the request.</set-body>
</return-response>
</otherwise>
</choose>
</inbound>
<backend>
<base />
</backend>
<outbound>
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>In the policy above a random number is generated that is greater than or equal to 1 and less than 3 using the Next method. The application’s request is sent along to one of the two backends based upon that number. You could add additional backends by upping the max value in the Next method and adding another when condition. Pretty awesome right?
Before you ask, no you do not need a health probe to monitor a cloud service provider managed service. Please don’t make your life difficult by introducing an Application Gateway behind the APIM instance in front of the AOAI instance because Application Gateway allows for health probes and more complex load balancing. All you’re doing is paying Microsoft more money, making your operations’ team life miserable, and adding more latency. Ensuring the service is available and health is on the cloud service provider, not you.
But Matt, what about taking an AOAI instance out of the pool if it beings throttling traffic? Again, no you do not need to this. Eventually this APIM as a simple load balancer pattern will not necessary when the AOAI service is more mature. When that happens, your applications consuming the service will need to be built to handle throttling. Developers are familiar with handling throttling in their application code. Make that their responsibility.
Well folks, that’s this short and sweet post. Let’s summarize what we learned:
- This pattern requires Azure AD authentication to AOAI. API keys will not work because each AOAI instance has different API keys.
- You may hit the requests/minute and tokens/minute limits of an AOAI instance.
- You can request higher limits but the request takes time to be approved.
- You can create multiple instances of AOAI to get around the limits within a specific instance.
- APIM can provide simple randomized load balancing across multiple instances of AOAI.
- You DO NOT need anything more complicated than simple randomized load balancing. This is a temporary solution that you will eventually phase out. Don’t make it more complicated than it needs to be.
- DO NOT introduce an Application Gateway behind APIM unless you like paying Microsoft more money.
Have a great week!