Hello once again fellow geek. In this post I will be continuing my series of NSPs (Network Security Perimeters). Over the past few posts in this series I’ve explained the problem NSPs solve, the components that make up an NSP, demonstrated NSPs through a Key Vault use case and an AI workload use case, and even shown how they can used to troubleshoot the dreaded Private Endpoints and forward web proxy problem we all run into. After reading those posts you are probably wondering why you aren’t seeing them more talked about in the Azure world. Besides the fact it’s not called “Frontier Network Agentic Security AI Perimeter”, the reason NSPs haven’t been getting the love they should is due to a technical gap that is finally in the process of being lifted.
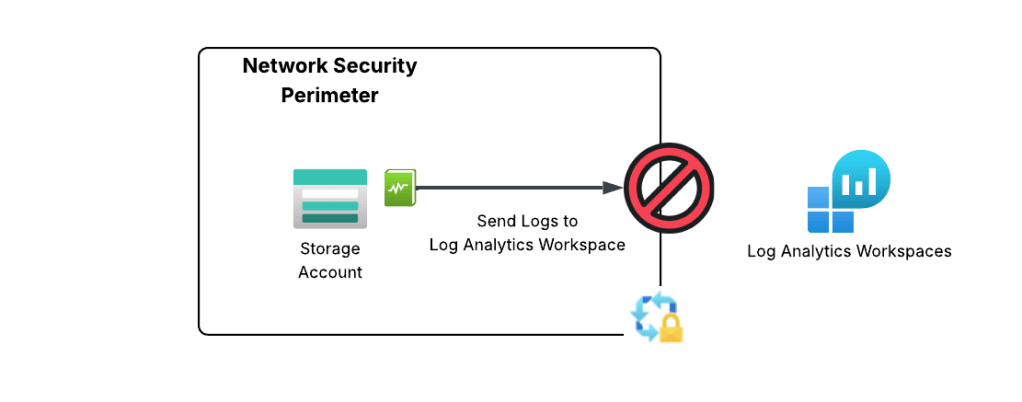
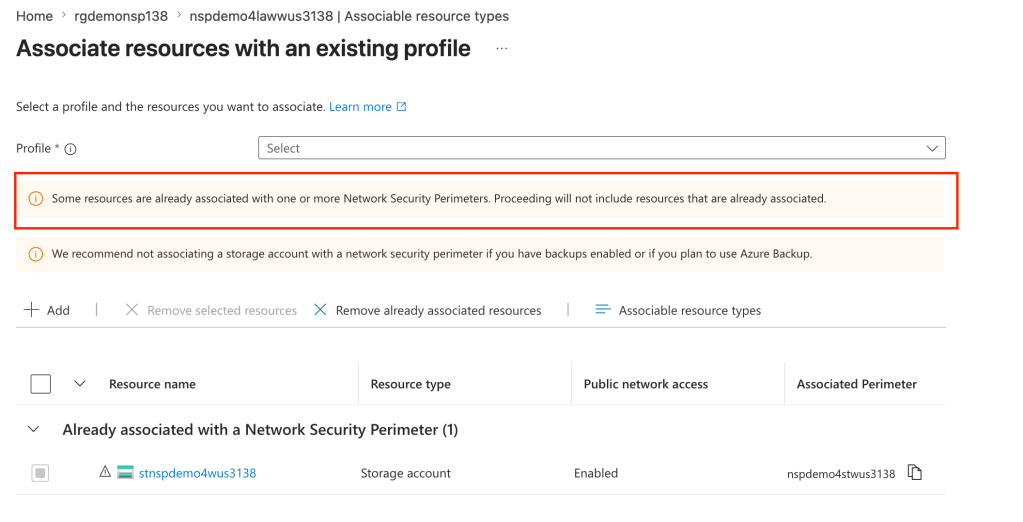
The only way to work around this limitation is to place the delivery destination (LAW, storage account, event hub) in the same NSP. While this sounds like a simple solution, a given resource can only belong to a single NSP. If you attempt to add a resource to an NSP when it’s already associated to another NSP it will fail as seen below.
Resources can only be associated to a single NSP
If you’ve ever done logging as scale in Azure, you already see the problem with this limitation. When logging at scale in Azure, it’s very common to send logs to a centralized Log Analytics Workspace, Event Hub, or Storage Account. There are a number of benefits to doing this beyond the scope of this post which you can read about in the CAF (Cloud Adoption Framework) documentation. These resource are typically managed by a security team or a platform team and live in subscriptions controlled by those teams.
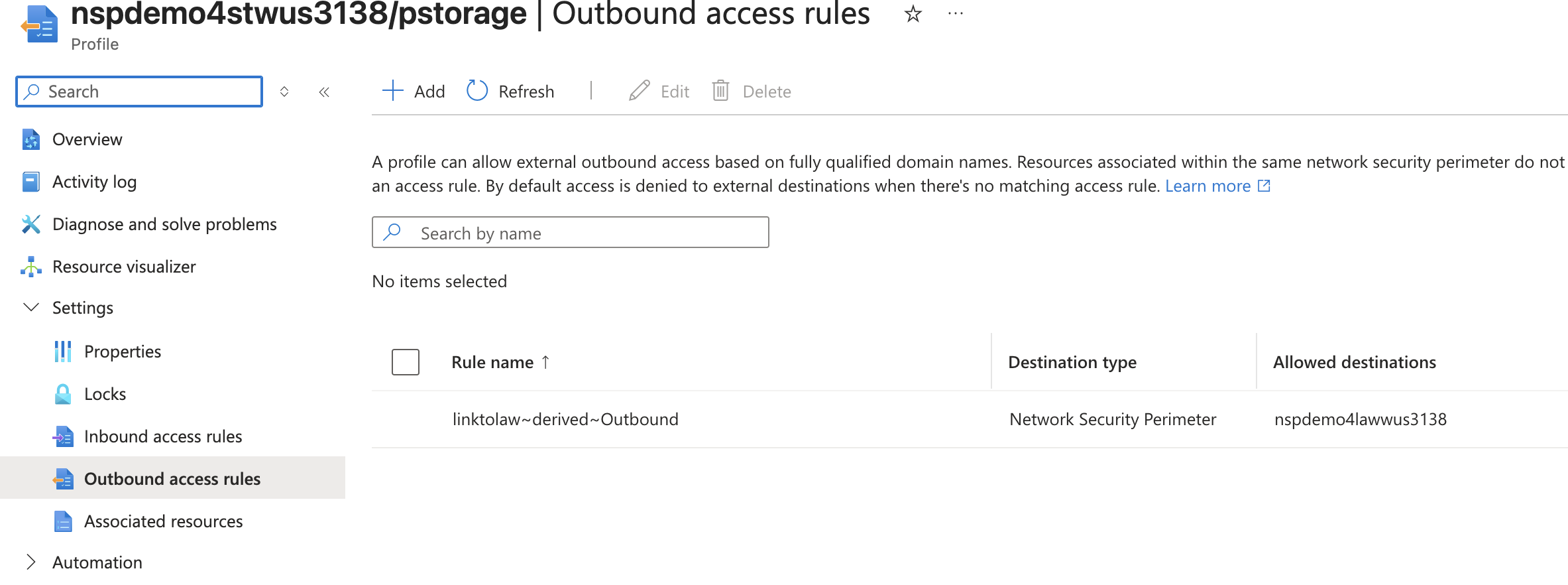
If you’re like, your first instinct is to create an outbound rule to allow the access to the Log Analytics Workspace. Good instinct, but not possible because today NSPs only support outbound rules of type FQDN and there is no FQDN for platform diagnostic logs that Microsoft provide today. A service tag would be the best bet, but sadly it is not yet supported for NSP outbound rules.
Centralized logging problem with NSPs
Up until very recently, NSPs in enforcement mode have been pretty much a non-starter for enterprise customers due to this limitation. Notice I say “enforcement”. If you aren’t using NSPs in learning (or transition mode) you are losing out on insanely valuable egress visibility you can’t get using any other means as I describe in my troubleshooting post.
The PG (Product Group) for NSPs is one of those amazing product groups who listens to the customer, wants to see their product adopted, and works their butt off. Just a few weeks ago they introduced a new feature into public preview that begins to address this technical limitation
The Solution
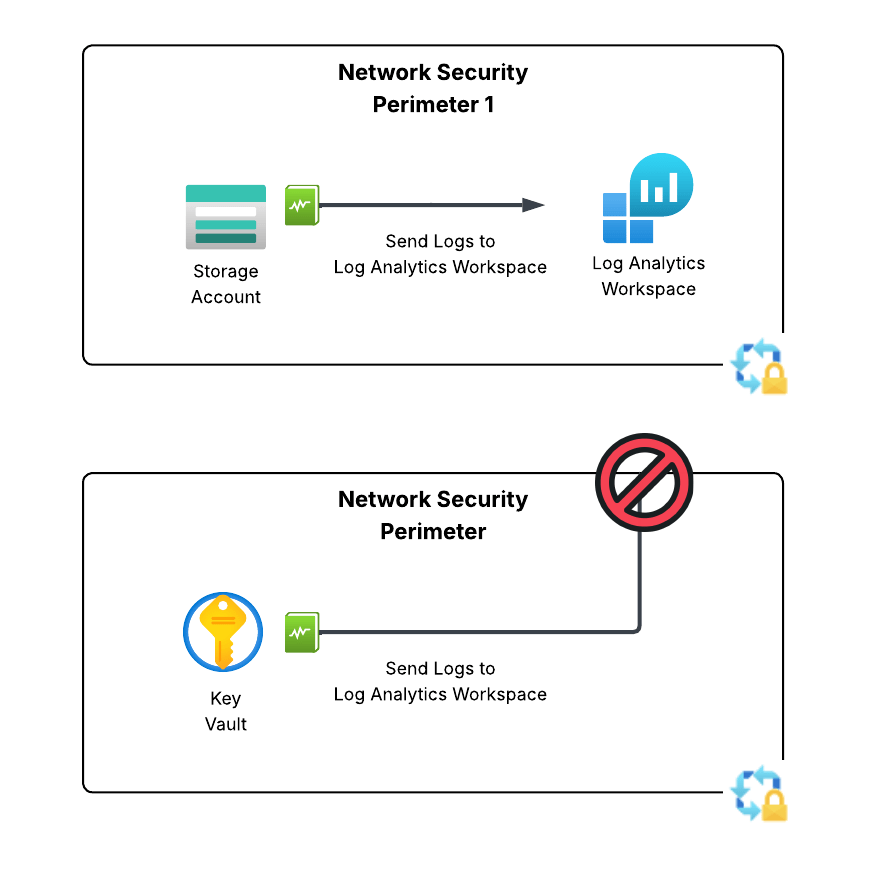
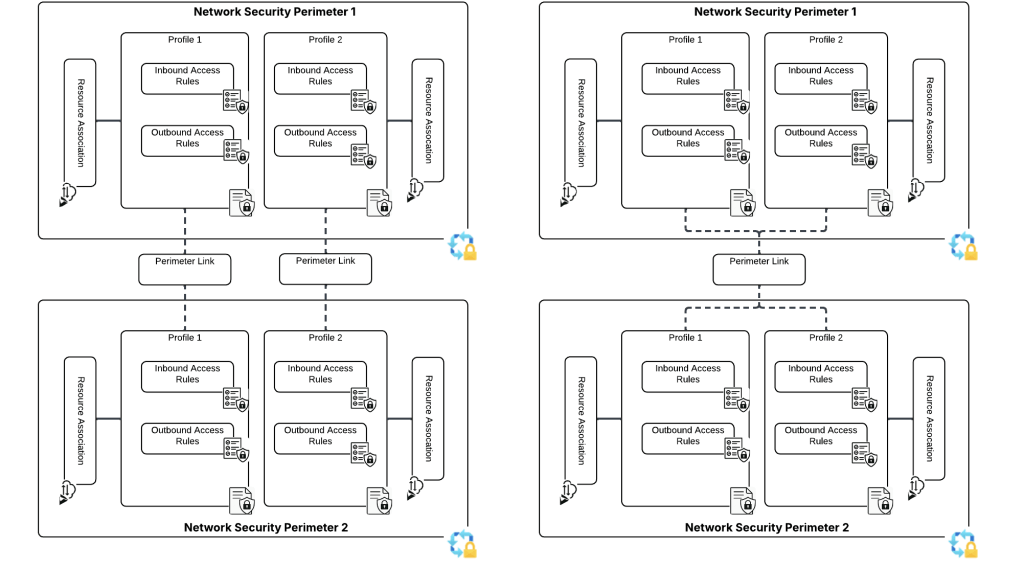
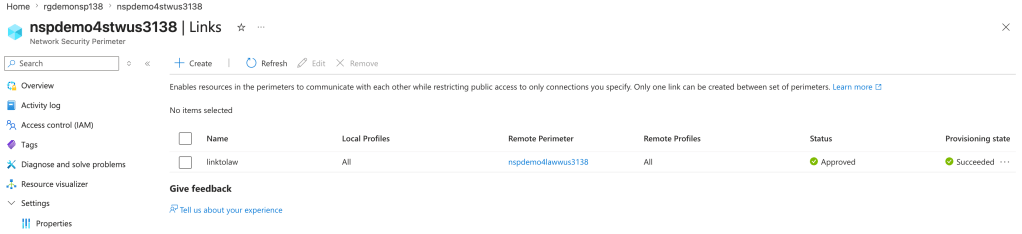
The solution for this technical problem is perimeter links. In the ARM (Azure Resource Manager) API, these are referred to as links and are a child resource of the Network Security Perimeter. Perimeter links allow traffic to flow between NSPs either per profile or for all profiles. This means we can slap a perimeter link between the NSP containing our resources that need to deliver our logs and the NSP containing the resource we’re delivering the logs to!
Perimeter links can be across a single profile or all profiles within an NSP
In the image below I’ve created a perimeter link between an NSP containing a storage account the NSP containing the log analytics workspace the storage account diagnostic log setting has been configured to deliver logs to. This link enables the traffic to flow freely between the two NSPs.
Perimeter link example
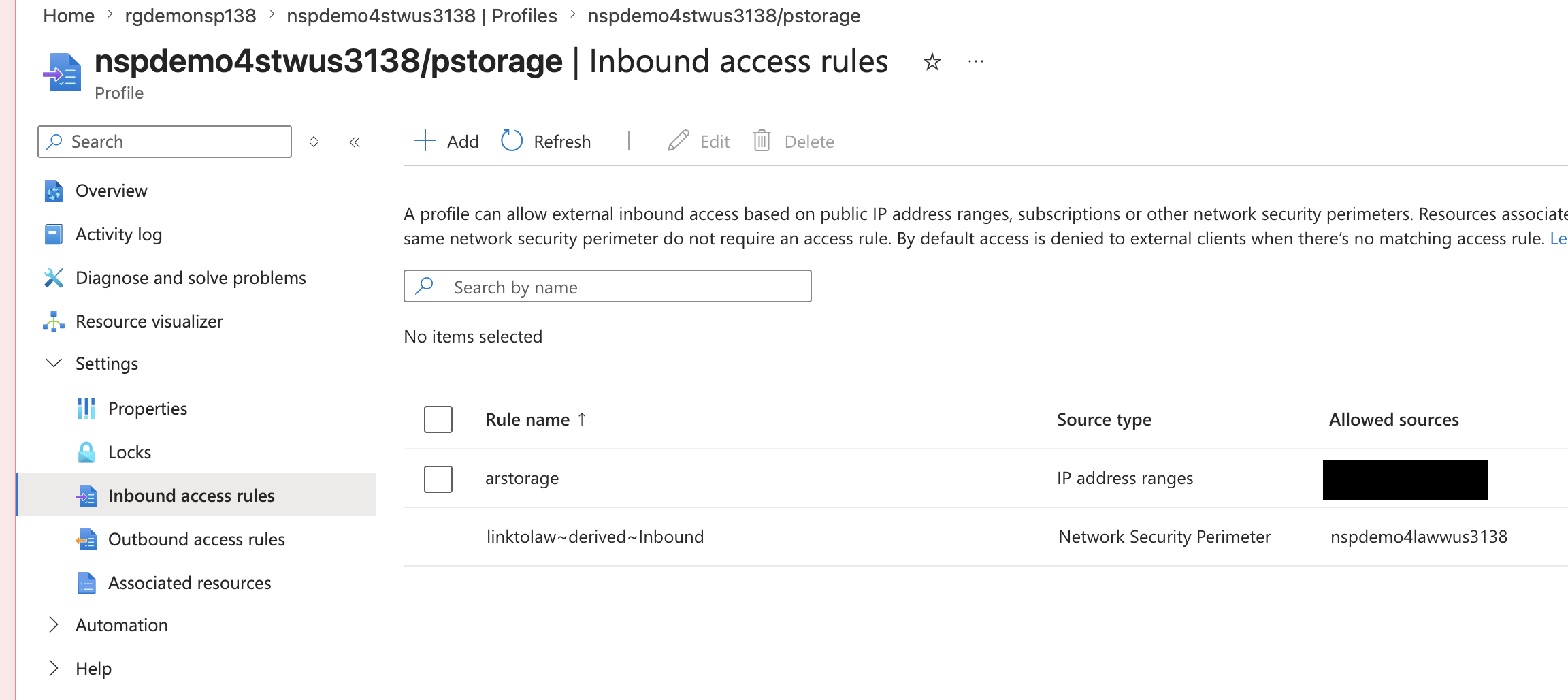
Once the perimeter link is created, new inbound and outbound access rules are created in each profile allowing the two NSPs to communicate with each other.
In the example above, once the perimeter link is in place and rules have been automatically created and taken affect (takes about 10-15 seconds) the spice will flow! Alright, logs will flow but I’ve been re-reading Dune so leave me alone in my nerdy world. In the screenshot below you can see the logs being blocked initially and then being allowed after the perimeter and its automatically created rules take affect.
The spice will flow!
The good and gotchas of perimeter links
So first some of the good things about perimeter links:
You can now do cross perimeter communication.
In my testing, terraform state doesn’t get botched up when the perimeter link triggers the automatic creation of the access rule. A reapply after didn’t complain and didn’t overwrite them.
Perimeter links work across subscriptions. Note there is a (as there should be) to make that work.
The biggest pain point of them right now is the maximum amount of perimeter links per NSP is 10. Obviously, this is no where near the scale needed for the centralized logging use case. However, this is still preview and I’m confident the PG will increase that limit (hopefully a shit ton) prior to GA.
Well folks, let me leave you with a few recommendations:
If you’re not using NSPs as a detective control for data exfiltration you are missing out. You need to make this a priority, if only for the visibility into egress.
This is preview, so muck around with it, but don’t go rolling this to prod.
Welcome back folks. Today I’ll be continuing my deep dive series into Entra. In my last post I went over the basics of Entra ID covering what it is at a high level and the important resources you’ll want to understand to grasp how human and non-humans identities are treated within the service. One of the features of Entra ID that I highlighted in that post was that it provides authentication services. It is capable of providing authentication of a human or non-human through older protocols like Kerberos (don’t get me started on this feature or else I’ll spend the whole post ranting) and LDAP (through Entra ID Domain Services, another service I’m no fan of), but also more modern protocols such as SAML and OIDC (OpenID Connect). Before I dive into Microsoft’s implementation of OIDC and the protocol it’s built on top of, OAuth, I figured it was a good time to do a light protocol primer (primarily for my own benefit because I can only re-read the RFC so many times before it stops being fun. Yeah I find it fun to read a good RFC, so what?).
What is OAuth?
You are probably thinking, “Why the hell are we talking about OAuth?” We need to talk about OAuth (Open Authorization) because OIDC is built on top of the OAuth protocol. If you have a basic understanding of OAuth, then OIDC makes a lot more sense. I’m not going to try to make you an expert, because to make you an expert I’d need to expert which I am very far from. Instead, I’m going to give you the basics. If you want a better/smarter explanation, start with the RFC(s) and then take a read through Vittorio Bertocci’s (an industry legend) many articles, ebook, and videos online.
There are a lot of misconceptions out there where folks will talk about OAuth authentication, which is not a real thing. OAuth itself exists as an authorization protocol to provide a framework (lots of SHOULDs/COULDs and not a ton of MUSTs in that RFC) for how applications can get limited access to a user’s data based around the user’s consent using delegation.
The protocol refers to this limited access as a scope. The assignment of a specific scope to an application gives you the ability to do delegation vs impersonation. In impersonation, the application will typically act as you with your full permission set vs with delegation you grant consent for the application to access a subset of your data with a more restricted set of permissions. A good example would be delegating the application the read permission over your email vs the reading, writing new emails, and deleting emails impersonation might give the application.
When it comes to the whole process of a user delegating a scope of access to an application, a number of different roles are involved. These roles include:
Client
Resource Owner
Authorization Server
Resource Server
Client
The client is an application that needs to access some data. Within the protocol it’s important to divide applications into a few different buckets, because the protocol supports them in different ways as I’ll cover in a bit. The standard breaks them into three buckets: web applications, browser-based applications, and native applications. I’m going to keep it simple and consolidate those three buckets into two which will be web applications and non-web applications.
Clients can be either public clients (non-web apps) or confidential clients (web apps). Confidential clients have some type of credential they use to authenticate themselves to the authorization server while public clients do not have a credential (because their code runs on the user’s machine so there is no way to secure the credential). Clients must register with the authorization server either through dynamic registration (which Entra ID does not support today) or through some other type of process. Registration, at a minimum, will include providing the authorization server with a redirectUri, which grant types it will use, and whether it’s a public or confidential client. The client is then issued a unique identifier called a client_id and optionally a client_secret if a confidential client. We’ll see an example of how Entra does it later on this series. Examples of clients could be applications you develop, third-party applications you integrate with, or Microsoft-native applications like Microsoft Teams.
Resource Owner
The resource owner is the user or organization that owns the data the client wants to access and is the entity that is capable of granting access to that data through a consent process. Consent is a major focus in OAuth since it relies on delegation of a specific scope of access to the data. Consent is the process of the resource owner approving that delegation. Resource owners in the Entra ID world are going to be the enterprise at the top layer, business units underneath that layer, and finally its employees which are represented by user objects in Entra. Consent will either be granted for all users within the tenant by an administrator or by individual users to data they have permissions over. In Entra, which consent is required is defined by the type property in the application resource’s permissionScope.
Authorization Server
The authorization server is the role that glues all other roles together. This is the server authenticates the user (OAuth doesn’t care how), gets the user’s consent for the client to access the data, and issues an access token to the client. Entra ID fulfills this role in the Microsoft cloud world.
Resource Server
The resource server hosts the resource owner’s data. It will consume the access token obtained by the client from the authorization server and allow or deny access to the data. Resource servers in the Microsoft world could be your custom built application or the Microsoft Graph API.
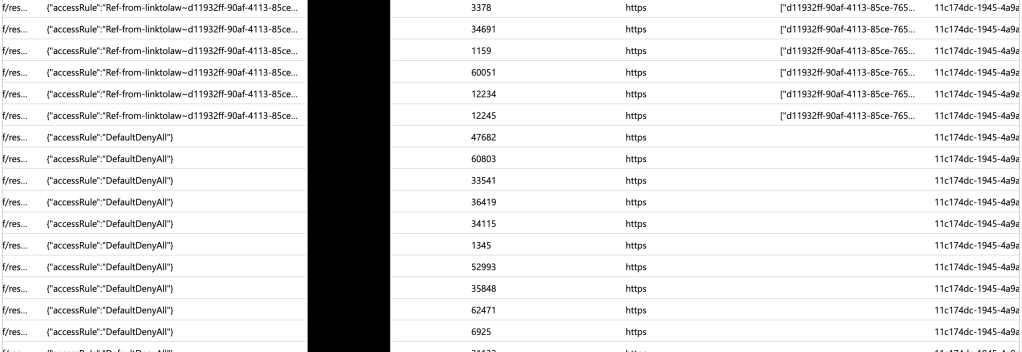
The RFC has a basic diagram which does a good job explaining the flow at a high level.
High level OAuth flow
You’ll notice the the term authorization grant in the above image. An authorization grant represents the resource owner’s authorization (delegation) of a specific scope of access to their data and is used by the client to get an access token which the resource server consumes and approves/denies access. In the base specification for OAuth 2.1, there are three types of grants (there are a ton of extension grants, some of which we’ll cover in this series) which include the authorization code grant, the refresh token grant, and the client credentials grant.
Before I describe the grant types, it’s worth calling out that I’m going to be talking specifically about OAuth 2.1 (which is still a draft RFC right now). OAuth 2.1 seeks to address a lot of the security issues with OAuth 2.0. In OAuth 2.0 there were a bunch more grant types including resource owner credentials flow and the implicit flow there are somewhat of security nightmares. OAuth 2.1 removes those grant types and the official spec sticks to the three I described above while adding an additional requirement for PKCE (Proof-Key for Code Exchange) for both public AND confidential clients. PKCE helps to address authorization code interception attacks. This Okta article does a great job describing the security benefit brings. I’ll demonstrate this with MSAL in a later post. Now back to the authorization grant types.
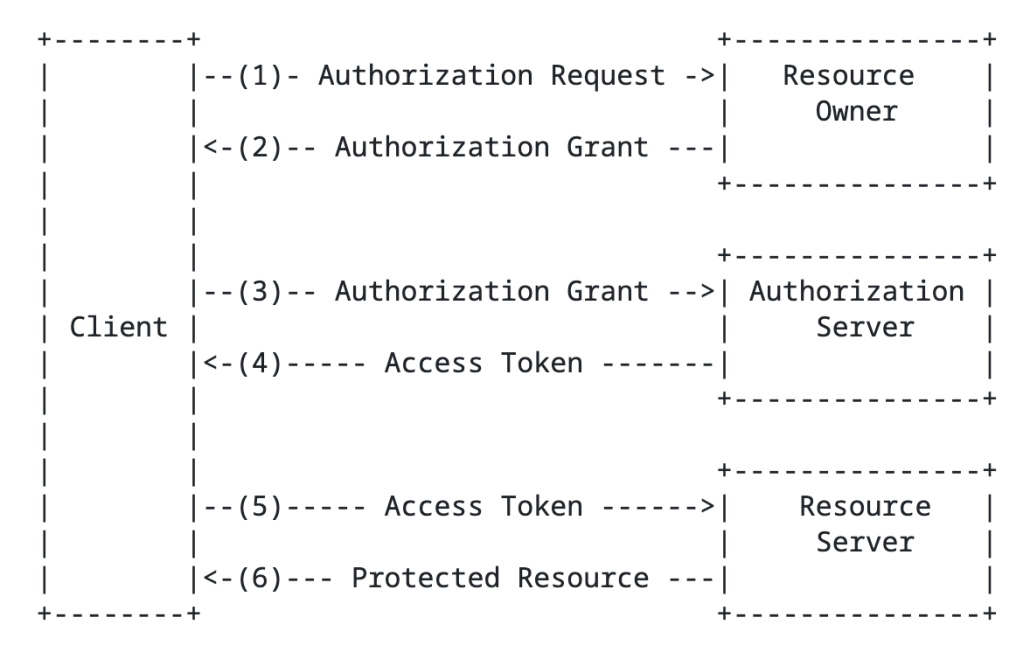
The authorization code grant type involves sending the resource owner to the authorization server to authenticate and consent to the client’s access of their data, returning an authorization code to the client, and the client exchanging that with the authorization server for an access token. This is going to be your go to grant type any delegation use case. An example of this would be an application accessing my data in a storage account that belongs to me.
Authorization Code Flow
Next up is the client credentials flow grant type. In this flow there is no user consent because the data the client is trying to access is under its control. Essentially, the client uses its own identity context to access the data because it’s already been authorized to do so. An example here would be an application pulling Entra ID sign-in logs from the MS Graph API.
Client Credentials Flow
Lastly, we have the refresh token grant. This grant type is used by the client to exchange a refresh token for a fresh access token. Access tokens must be short lived (typically around an hour). Instead of having the resource owner go through the whole authentication and consent process again, the client can exchange its longer living refresh token (if it requested one) for a new access token of the same or lesser scope.
In addition to grant types above there are extension grant types. The one that will be relevant to this series is the jwt bearer type, or more formally the JSON Web Token (JWT) profile. In the Microsoft world, you’ll see this referred to as the on-behalf-of flow. This is the flow that Microsoft will use for any multi-hop OAuth. There is also another newer grant type to be aware of which is the token exchange flow. This has a similar use case as the jwt bearer flow for multi-hop OAuth but isn’t limited to JWTs and provides additional information in the access token which can be very helpful in identifying client (actor) vs the resource owner (subject) in the access token. Entra doesn’t support this flow to my understanding, so you’ll be using jwt-bearer instead for multi-hop flows as we’ll see in a future post.
In an authorization request will look something like the below:
GET /authorize?response_type=code&client_id=s6BhdRkqt3&state=xyz
In the above example we see the client is requesting the authorization code grant type, is specifying its client id and its redirect_uri (which were established during client registration), a code challenge (for PKCE), and the scope of access it is requesting.
Access tokens come in a few flavors which you can read about in the RFC. The most common type of token is a bearer token within Entra’s implementation. The bearer token is exactly what it sounds like, whoever bears the token holds the power! Bearer tokens are typically JWTs (JSON Web Tokens). While RFC doesn’t specifically require the access token to be cryptographically signed, the ones that Entra ID issues are. The public key used to verify the signature can be obtained for Entra ID from a public metadata endpoint we’ll see later.
There are a few important endpoints the client needs to know about for the authorization server. This includes the authorization endpoint (where the resource owner is sent to authenticate and consent) and the token endpoint (where the client obtains an access token). These can be retrieved via a metadata endpoint. This is how Entra ID does it as we’ll see in a future post.
Ok, with that you should now have a high level understanding of OAuth and be aware of its role as an authorization protocol. Key in on that word, authorization. When I perform an OAuth flow I get an access token back to my app that I can use to access a resource owner’s data, but I would still need to authenticate the user to my application and get some basic profile information via another means. In comes OIDC.
What is OpenID Connect?
Like the prior section, my goal is give you a primer. If you want the gory details, take a read through the specification (another tolerable if not enjoyable read). Microsoft and Auth0 have solid one pagers if reading specifications isn’t your style.
The OIDC protocol is built on top of the OAuth (Open Authorization) protocol to provide an identity layer and authentication layer. It gives us the means get some assurance that the user is who they say they are and get some basic information about the user.
Within the OpenID protocol there are three roles that exist. These include:
End User
RP (Relying Party)
OP (OpenID Provider)
Since the protocol is built on top of the OAuth protocol, these roles will map nicely to the OAuth roles as we’ll see.
We first have the end user. The end user is the human participant that will be access our application. They are very often also the resource owner for any data we may want to access about them as we’ll see later.
Next, we have the RP. The RP is the application that is requesting end user authentication and claims (or data/attributes) about the user. This will be an OAuth client application.
Finally we have the OP. The OP is the server capable of authenticating the user and providing claims about the user’s identity. This role is fulfilled by the OAuth authorization server in all instances (I don’t believe their are exceptions, but feel free to correct me) .
The OP will issue a security token referred to as an id token with claims about the authentication of the end user, including claims about the user.
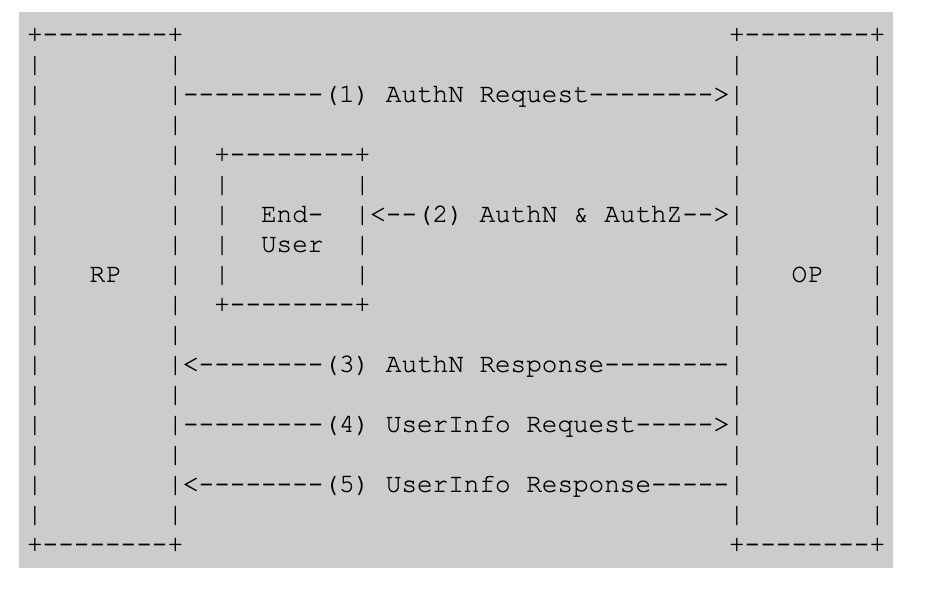
This is another instance where the specification did a great job with a high level flow diagram.
High-level OIDC Flow
The structure of the authentication request is almost identical to the structure of an authorization request in OAuth.
GET /authorize?response_type=code&client_id=s6BhdRkqt3
Notice above that we have an added state and nonce. The state helps to provide CSRF (cross-site request forgery) attacks, such as fooling the victim into accessing an attacker’s account to get them to upload data or perhaps purchase things for the attacker’s account. The nonce helps to mitigate id token replay attacks (app validates the nonce in the id token matches what it expects for the user’s session). Now the major things to pay attention to is the additional scopes. Here we see the openid and profile scopes. The openid scope tells the OP the client is looking for an id token. The profile scope is an optional scope which tells the OP to include additional claims in the id token such as the user’s name, preferred_username, and the like.
Once the RP (client / application) exchanges its authorization code (think authorization code grant) to the OP/authorization server, it returns back the an OIDC id token in addition to the OAuth access token. The application can then use the claims in the id token to identify the user, get information into how the user authenticated, get group information, and anything else you can stuff into the claims. It gives the application context about the user.
Below is an example id token’s payload. ID tokens follow the JWT standard and are cryptographically signed by a private key held by the OP. Clients will need to verify the signature using the OPs public key which is usually published in the OIDC discovery endpoint which looks something like this https://{issuer}/.well-known/openid-configuration. We’ll see an example when we break down Entra’s implementation.
At this point you should have a reasonably decent high level understanding of OAuth/OIDC. If you are already an “expert” you likely snorted milk through you nose reading my shitty explanation. What I mainly want you to take away from this is that OAuth is an authorization protocol with OIDC providing an authentication layer nicely on top. I like to think of OAuth as the cake with OIDC as the frosting. That top layer doesn’t work without the bottom layer (you freaks that eat the frosting right out of the can shall remain silent) and the bottom layer is enriched by the frosting on top. It’s 7PM and I’m craving a sweet, lay off.
In my next post I’ll walk through building out the required components in Entra ID for the frontend application. You’ll read and recognize properties that translate directly back to these two protocols. Other properties may not have the same name, but you’ll understand why they exist.
With Memorial Day weekend coming quickly, I wanted to get the second post to this series out before the knowledge my late nights with Red Eye coffee brought leaks from my brain. In my last post I did a walkthrough of the Publishing Agents To Teams feature of the Foundry Agent Service within Microsoft Foundry. In that post I covered the Portal experience, broke open some of the black box as to my understanding of the workflow that happens underneath when you push the publish button, and talked through the AI Bot Service’s role in the feature. For this post I’m going to cover a possible network architecture to support this feature when security controls are required around inbound and outbound network access (I mentioned a few last post), the network flow for that architecture, and some of the switches and knobs you can turn to add additional security beyond the basic layer 4 network controls. After that, I’m going to walk through a Jupyter Notebook I put together than shows you how to perform the steps behind the publish button programmatically. If you haven’t read my last post, Graeme’s blog post on this topic, and Moim’s blog post on reverse engineering Bot services you should do that before you try to tackle this one.
A Possible Architecture
As I covered in my last post, when we want to make an agent available in Teams we need Teams to be capable of reaching it. In this design, with Teams interacting with the AI Bot Service which relays the information to our agent, this means we need to make the agent’s messaging endpoint available to the Microsoft public backbone (i.e. it needs to be exposed via a public IP address). Graeme provided one architecture to accomplish this which will work for a number of folks. I foresee a few different architectural options:
APIM v2 configured for public inbound and regional vnet integration
APIM classic configured for external mode
App Gateway with a public listener with APIM v2 VNet Injected or PE + regional vnet integration behind it
App Gateway with a public listener with APIM classic VNet injection behind it
Firewall DNAT + APIM v2 VNet Injected or PE + regional vnet integration behind it
Firewall DNAT + APIM classic VNet injection behind it
For this post I’m going to focus on the 3rd option which has Application Gateway sitting in front of an v2 tier API Management. I like this pattern because I get the WAF, SNI, host-based routing, and path-based routing benefits of an App Gw (Application Gateway) and avoid slapping a public IP on my APIM (API Management). There is more complexity to this pattern, but more security and flexibility always comes with more complexity, right?
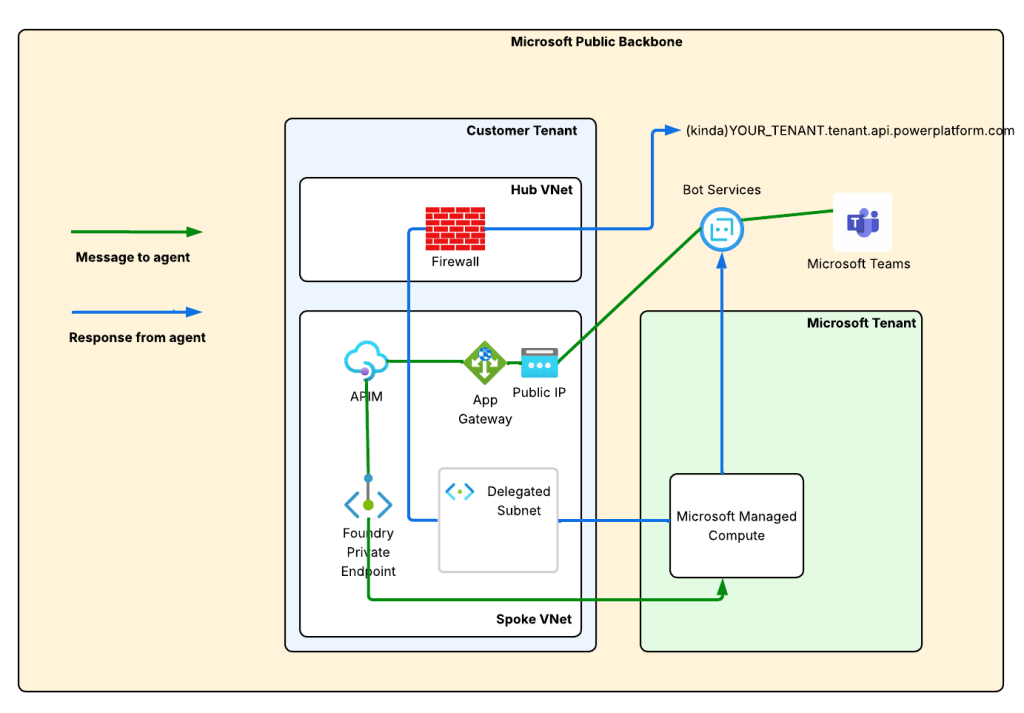
Generally my traffic will look something like the image you seen down below.
The green line is the incoming message from the Microsoft Teams. We see it is relayed from the Teams Service to the public IP address of the AppGw via the Bot Service. From there, we send it through the APIM and finally on to the Private Endpoint for Foundry which tunnels it on to the Microsoft-managed compute behind the Foundry Agent Service.
The blue line is the response from the agent. You’ll notice there are two blue lines. Based on the logs in my firewall when I tested this, I did not see the response traffic back to the Bot Service (this would be the endpoint in the serviceurl in the JWT received from the Bot Service which should be something like smba.trafficmanager.net). I’m making the assumption that this traffic isn’t egressed through the customer virtual network and instead flows out whatever path Microsoft is providing in the network where the managed compute lives that hosts the agent runtimes. Additionally, you’ll notice a blue line flowing through my virtual network and headed to an FQDN at tenant.api.powerplatform.com. I’m still trying to get clarification on if this flow is truly required and what it’s for.
The first instinct of us old networking farts is to look at this diagram and think this is asymmetric routing. However, in this situation it isn’t because the green and blue flows are separate TCP sessions because the message and response sequence is asynchronous.
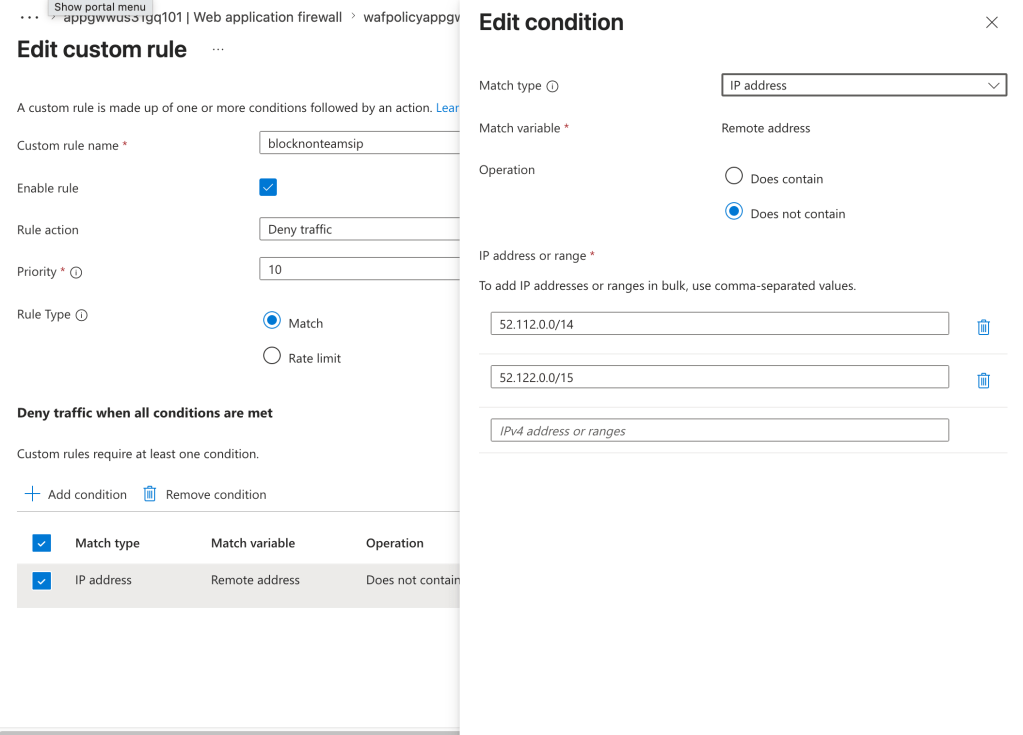
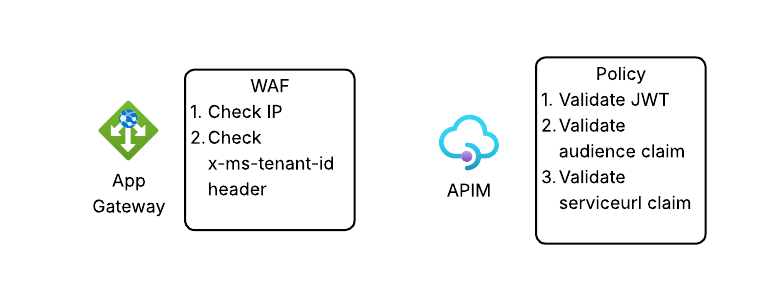
Given we’re starting with AppGw we can use the WAF functionality to validate the source IP address is coming from the Teams service. A simple rule like the below will do that check.
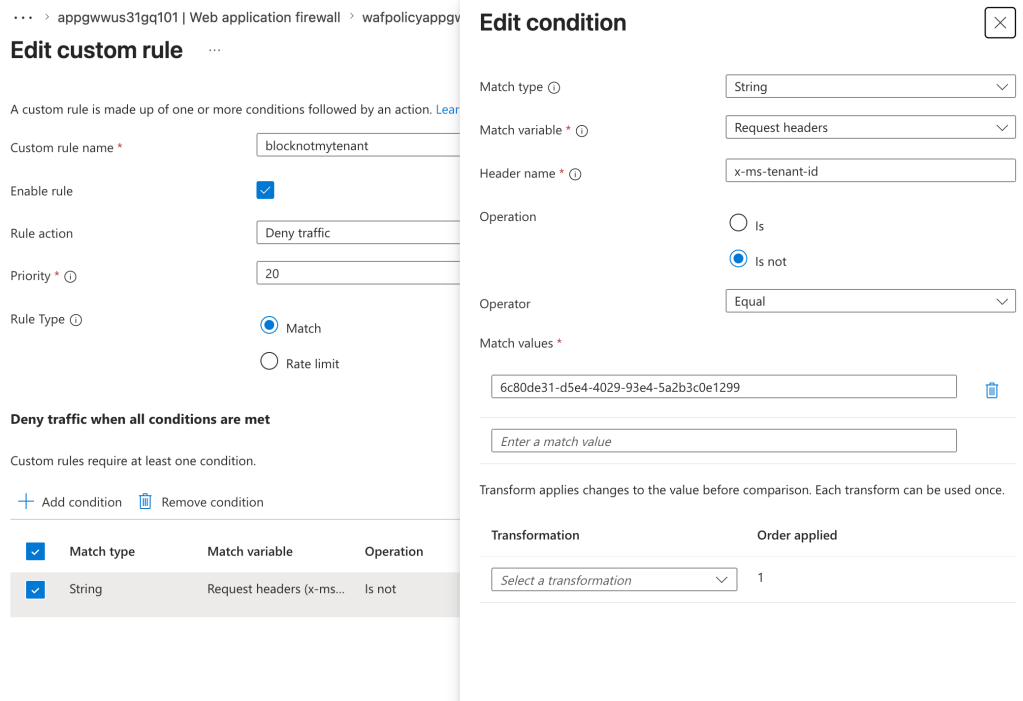
Next, I want to validate the request header of x-ms-tenant-id to validate that the header is present and contains my tenant id.
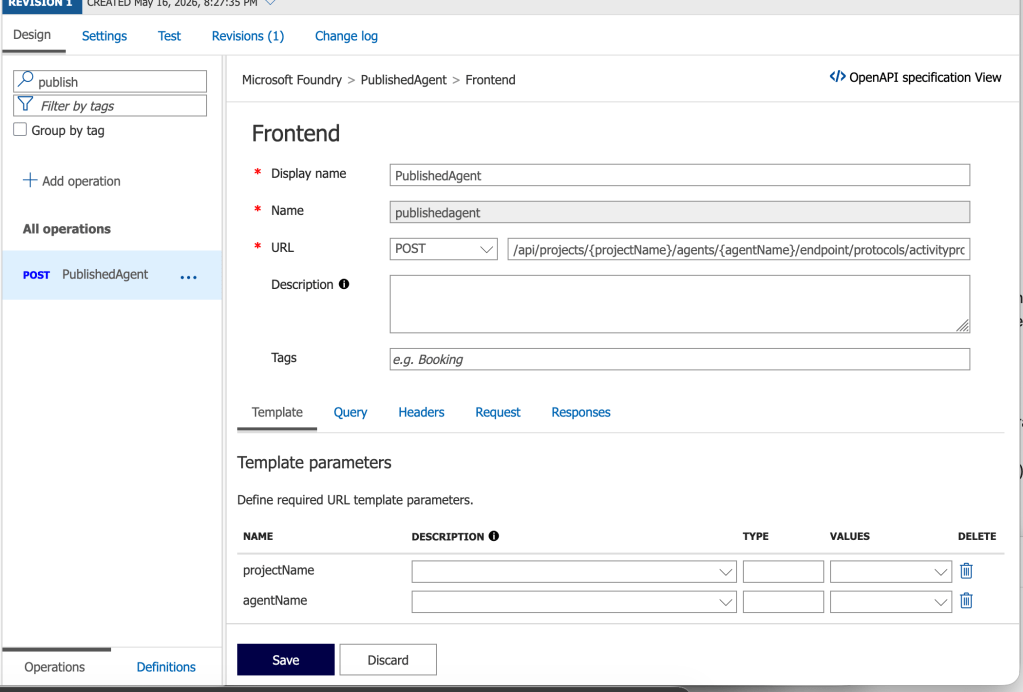
Next up I have APIM. Here I’ve created an API with an operation named PublishedAgent. The operation is defined as you see below.
Within the operation, I’ve taken Graeme’s policy and made a small tweak to it to validate the serviceurl claim in the JWT and ensure it contains my tenant id.
If we bring it back up out of the weeds and to the high level, here is what we’re doing at each component in the flow.
So there you have it folks, that’s an architecture you could use and some of the details of getting it up and running. Now let’s bounce over and take a look at how to avoid the manual action of “pushing the pretty blue button” and look at how we’d publish a Foundry Agent programmatically.
Programmatic Setup
The kind folks over at the Foundry Agents PG (product group) put together a sample of the steps needed to do this programmatically with PowerShell and Bicep. Since I prefer good ole bash shell, Python, and Terraform I reworked their steps into a Jupyter Notebook which you can find here. There is a sample env file in the repository. You don’t need to populate the client id and client secret unless you want to play around with the commands in the appendix. Those are not required.
The first step in the process is creation of the Bot Service resource in Azure. As I covered in my last post, this resource mainly exists to store metadata about your bot (or agent in this scenario) that the AI Bot Service uses to relay data back and forth between Teams and the agent. You’ll want to create a new Bot Service which will require you have the specific permissions to do that (if you want to go the custom role) or something more generic like Contributor. You’ll also want to make sure the Bot.Service resource provider is registered in your subscription (pretty sure this requires Owner).
I’ve crafted a Terraform template for this step. Before you can create the Bot Service with the template, you need to collect some Entra ID-related information. First, you’ll need to fetch your Entra ID tenant ID. You can do this programmatically by running after logging into az cli using the command below.
az account show --query tenantId -o tsv
Now that you have you’re logged into az cli and you’ve grabbed the tenant id, your next step is to fetch the principal id (or appId) of the Entra ID Agent Identity associated with the Foundry Agent. You’ll associate this identity with the Bot Service resource. Before you do that, you’ll need to get fetch an access token with the appropriate scope.
from azure.identity import DefaultAzureCredential
from dotenv import load_dotenv
# Get a token for Foundry scope
credential = DefaultAzureCredential()
scopes = ["https://ai.azure.com"]
user_token = credential.get_token(*scopes)
Next you can use this function to grab the principal_id property.
print(f"Foundry Agent Principal ID: {agent_principal_id}")
print(json.dumps(agent, indent=2))
Once you have the tenant id and principal id of the agent identity associated with your Foundry Agent, you are almost ready to create the Bot Service. The last step is formulating your messaging endpoint. It will look something like this:
As I showed earlier, you can modify this to change the FQDN to point to your preferred ingress infrastructure and add pathing to the beginning to ensure proper routing through an API Gateway.
Now that you have everything ready to go you can run a Terraform template like the one located here. This will create the Bot Service and Teams channel child object and configure diagnostic settings with delivery to the specified (Log Analytics Workspace).
Once that is complete, you need enable the activity protocol support for your agent. You can do this using the code below:
import os
import json
import requests
from dotenv import load_dotenv
# Load environmental variables
load_dotenv(override=True)
# Function that enables the activity protocol for the agent and configures the required Bot Service authorization scheme
At this point, you have the Bot Service setup and you’ve activated the activity protocol for the agent so its now listening for requests at the messaging endpoint. The last step in the process is to use the publish operation and you will need the Foundry User role for this (as far as I can tell).
What exactly this does is still a bit of a black box for me, but it seems like it’s creating some type of API object to represent the agent in M365 Agent Registry (soon to be rebranded to Agent 365 I’m sure). Some of the APIs I need to poke around with require an Agents 365 license. Once I get that, I’ll update this section with more detail if I find exactly what it’s doing.
import os
import json
import requests
from dotenv import load_dotenv
# Load environmental variables
load_dotenv(override=True)
def publish_agent_teams(
subscription_id: str,
resource_group: str,
account_name: str,
project_name: str,
location: str,
agent_name: str,
agent_guid: str,
bot_id: str,
app_publish_scope: str,
publish_as_digital_worker: bool,
app_version: str,
short_description: str,
full_description: str,
developer_name: str,
developer_website_url: str,
privacy_url: str,
terms_of_use_url: str,
token: str
):
"""This function uses the Foundry API to publish a Foundry agent to Microsoft Teams
Args:
subscription_id (str): The Azure subscription ID where the Foundry account is provisioned
resource_group (str): The name of the resource group where the Foundry account is provisioned
account_name (str): The name of the Foundry account
project_name (str): The name of the Foundry project
location (str): The Azure region where the Foundry account is provisioned
agent_name (str): The name of the Foundry agent to publish
agent_guid (str): The GUID of the Foundry agent to publish
bot_id (str): The Microsoft App ID of the Bot registered in Entra ID for this agent
app_publish_scope (str): The scope to publish the Teams app to, either "Individual" or "Tenant"
publish_as_digital_worker (bool): Whether to publish the agent as a Digital Worker in Teams, which surfaces it in the Power Virtual Agents app in addition to allowing it to be installed as a standard Teams app
app_version (str): The version of the Teams app to publish
short_description (str): A short description of the agent to display in Teams
full_description (str): A full description of the agent to display in Teams
developer_name (str): The name of the developer or organization that created the agent, to display in Teams
developer_website_url (str): The URL for the developer's website, to display in Teams
privacy_url (str): The URL for the privacy policy for this agent, to display in Teams
terms_of_use_url (str): The URL for the terms of use for this agent, to display in Teams
token (str): The Entra ID access token with the scope of https://ai.azure.com/.default to authenticate the API request
Returns:
dict: The response from the Foundry API if the publish was successful, otherwise None
"""
body = {
"subscriptionId": subscription_id,
"agentGuid": agent_guid,
"agentName": agent_name,
"appRegistrationId": appRegistrationId,
"botId": bot_id,
"appPublishScope": app_publish_scope,
"publishAsDigitalWorker": publish_as_digital_worker,
"appVersion": app_version,
"shortDescription": short_description,
"fullDescription": full_description,
"developerName": developer_name,
"developerWebsiteUrl": developer_website_url,
"privacyUrl": privacy_url,
"termsOfUseUrl": terms_of_use_url
}
response = requests.post(
url = f"https://{location}.api.azureml.ms/agent-asset/v2.0/subscriptions/{subscription_id}/resourceGroups/{resource_group}/providers/Microsoft.MachineLearningServices/workspaces/{account_name}@{project_name}@AML/microsoft365/publish",
headers={
"Content-Type": "application/json",
"Accept": "application/json",
"Authorization": f"Bearer {token}",
},
json=body
)
if response.status_code == 200:
print("Agent published successfully! Status code: 200")
else:
logging.error(f"Failed to publish agent: {response.status_code} - {response.text}")
return None
publish_response = publish_agent_teams(
subscription_id = os.getenv("FOUNDRY_SUBSCRIPTION_ID"),
resource_group = os.getenv("FOUNDRY_RESOURCE_GROUP"),
account_name = os.getenv("FOUNDRY_ACCOUNT_NAME"),
project_name = os.getenv("FOUNDRY_PROJECT_NAME"),
location = os.getenv("FOUNDRY_LOCATION"),
agent_name = os.getenv("FOUNDRY_AGENT_NAME"),
agent_guid = enabled_agent_guid,
bot_id = enabled_agent_guid,
app_publish_scope = "Tenant",
publish_as_digital_worker = False,
app_version = "1.0.0",
short_description = "This is a sample agent published from Foundry to Teams",
full_description = "This agent was created in Foundry and published to Microsoft Teams using the Foundry API.",
developer_name = "Carl Carlson",
developer_website_url = "https://www.example.com",
privacy_url = "https://www.example.com/privacy",
terms_of_use_url = "https://www.example.com/terms",
token = user_token.token
)
This step is effectively the last step in the Foundry Portal publishing experience. If you installed it for an individual it will be immediately available for that user. If you publish it to the Teams App Catalog (tenant option) it will be put in a pending state until approved via the M365 Admin Portal.
And like magic, you have a programmatic way to emulate the magical blue button in the Foundry portal. If you’re curious as to what that API call is going to an AML (Azure Machine Learning) endpoint, that is because (today at least) Foundry is built on top of AML.
Summing it up
What I’ve hoped you gathered from here is publishing an agent to Teams isn’t as simple as pushing a button. Requirements needs to be gathered, a design needs to be worked out, services chosen, service properties chosen for security and scale, services load tested, and security controls properly implemented and any risks accepted.
You have a ton of flexibility with this design and my take is there is no optimal design. The optimal design is the one that provides you with the user experience you require aligned with the risks your org is willing to accept. If you’re building an agent that is hitting some public data source, maybe you don’t care about any of this infrastructure. Either way, do not just hit the publish button, group up with your peers across security, networking, operations, collaboration, and AI engineering and put your heads together to come up with a design you’re all happy with.
With that, I’m out for Memorial Day weekend. See you next time!
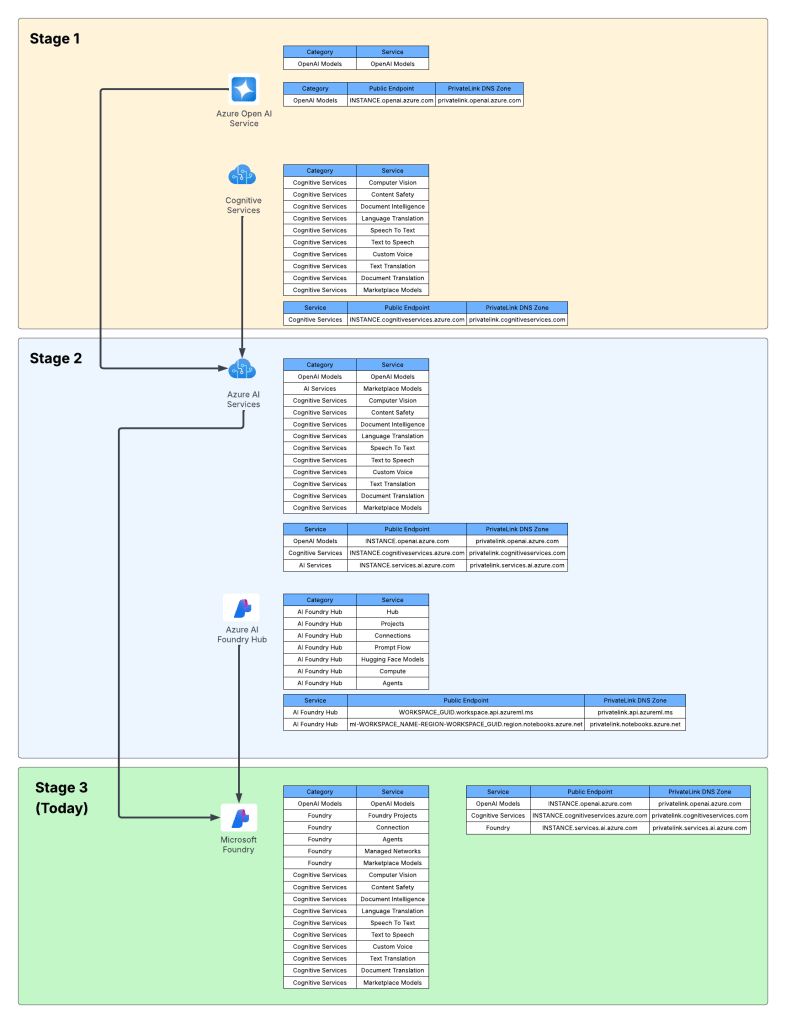
Hi folks! In the past I did a series on the Azure OpenAI Service and Microsoft Foundry Hubs (FKA AI Foundry Hubs FKA AI Studio). Instead of going through and updating all those posts and losing the historical content and context (I don’t know about you, but I love have the historical context of a service) I’m instead going to preserve it as is and spin up a new series on the latest iteration of Microsoft Foundry. I’ll likely keep much of the general framework of the older series because it seemed to work. One additional piece I’ll be included in this series is some of the quirks of the service I’ve run into to potentially save you pain from having to troubleshoot it. For this first post, I’m going to start this off explaining how the service has involved. As always, my persona focus here is my fellow folks in the central IT and infrastructure space.
The history
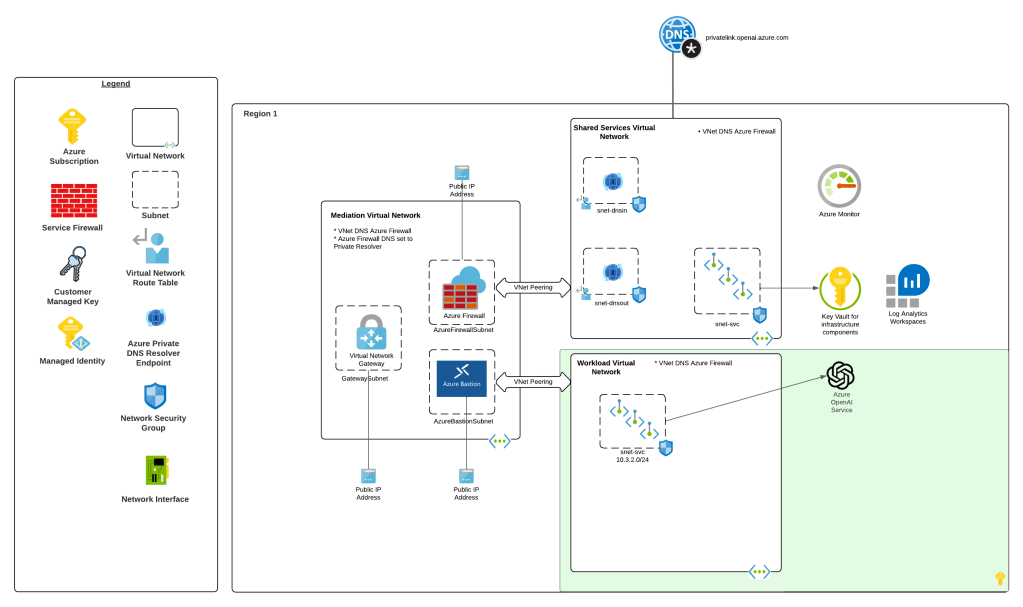
Way back in 2023 the hype behind generative AI really started go insane. Microsoft managed to negotiate rights to host OpenAI’s models in Azure and introduced the Azure OpenAI Service. The demand across customers was insane where every business unit (BU) wanted it yesterday. Microsoft initially offered the service within the Cognitive Services framework under the Cognitive Services resource provider. This mean it inherited many of the controls native to Cognitive Services which included Private Endpoints, a limited set of outbound controls, support for API key and Entra ID authentication, and support for Azure RBAC for authorization. Getting the deployed was pretty straightforward with the hold-ups to deployment being more concerns about LLM security in general. Deployment typically looked like the architecture below.
Azure OpenAI Service
As folks started to build their AI applications, they tapped into other services under the Cognitive Services umbrella like Content Safety, Speech-to-Text, and the like. These services fit in nicely as they also fell under the Cognitive Services umbrella and had a similar architecture as the above, requiring deployment of the resource and the typical private endpoint and authentication/authorization (authN/authZ) configuration.
I like to think of this as stage 1 of the Microsoft’s AI offerings.
Microsoft then wanted to offer more models, including models they have built such and Phi and third-party models such as Mistral. This drove them to create a new resource called an AI Service resource. This resource fell under the Cognitive Services resource provider, and again inherited similar architectures as above. Beyond hosting third-party models, it also included and endpoint to consume OpenAI models and some of the pool of Cognitive Services. This is where we begin to see the collapse of Microsoft’s AI Services under a single top-level resource.
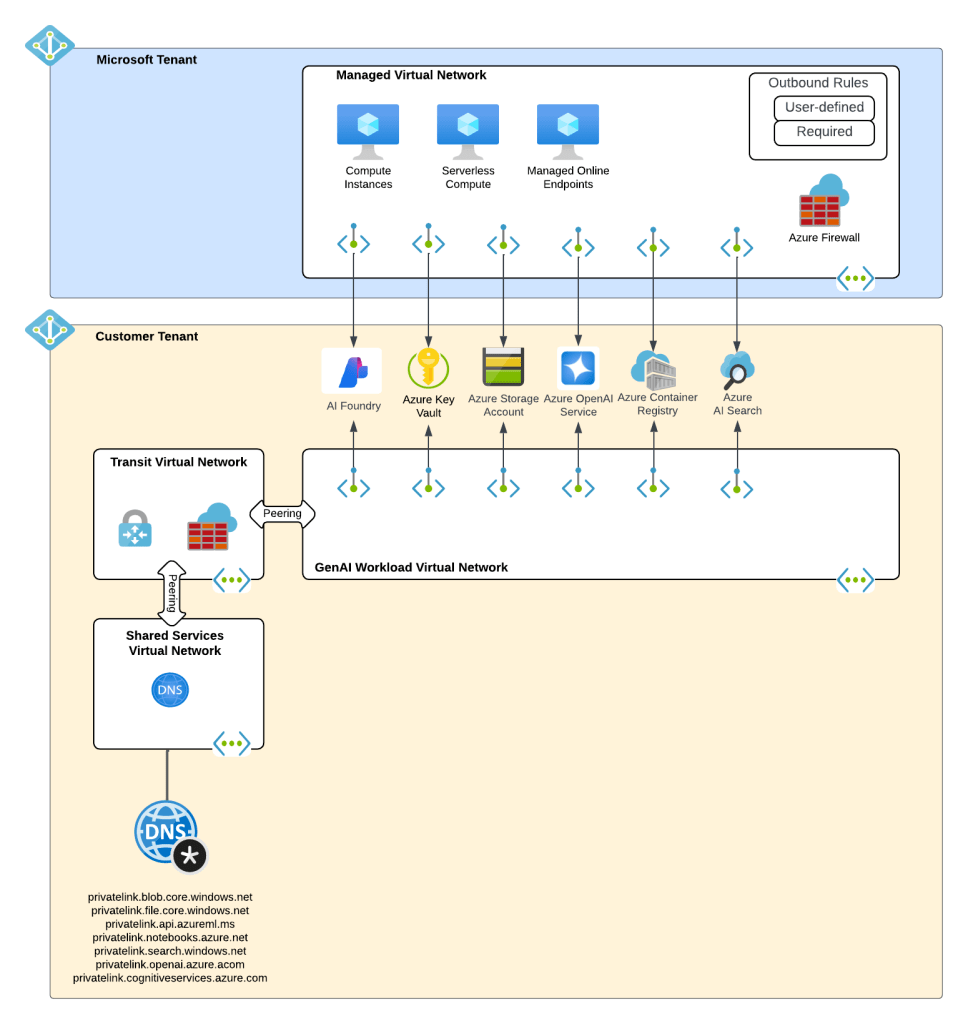
What about building AI apps though? This is where Foundry Hubs (FKA AI Studio) were introduced. The intent of Foundry Hubs were to be the one stop shop for developers to create their AI Apps. Here developers could experiment with LLMs using the playgrounds, build AI apps with Prompt Flow, build agents, or deploy 3rd party LLMs for Hugging Face. Foundry Hubs were a light overlay on top of the Azure Machine Learning (AML) service utilizing a new feature of AML built specifically for Foundry called AML Hubs. Foundry Hubs inherited a number of capabilities of AML such as its managed compute (to host 3rd party models and run prompt flows) and its managed virtual network (to host the managed compute).
Microsoft Foundry Hubs
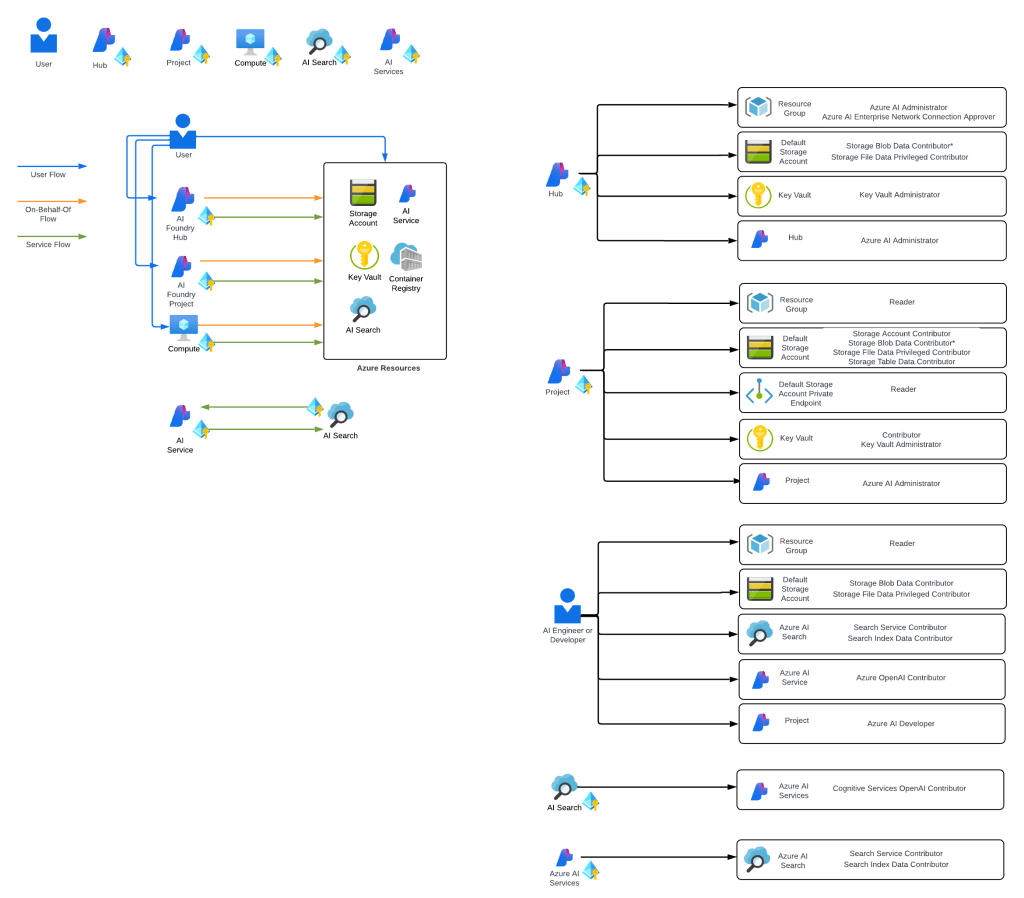
While this worked, anyone who has built a secure AML deployment knows that shit ain’t easy. Getting the service working requires extensive knowledge of how its identity and networking configuration. This was a pain point for many customers in my experience. Many struggled to get it up and running due to the complexity.
Example of complexity of Microsoft Foundry IAM model
I think of the combination of AI Services and Microsoft Foundry Hubs as stage 2 of Microsoft’s journey.
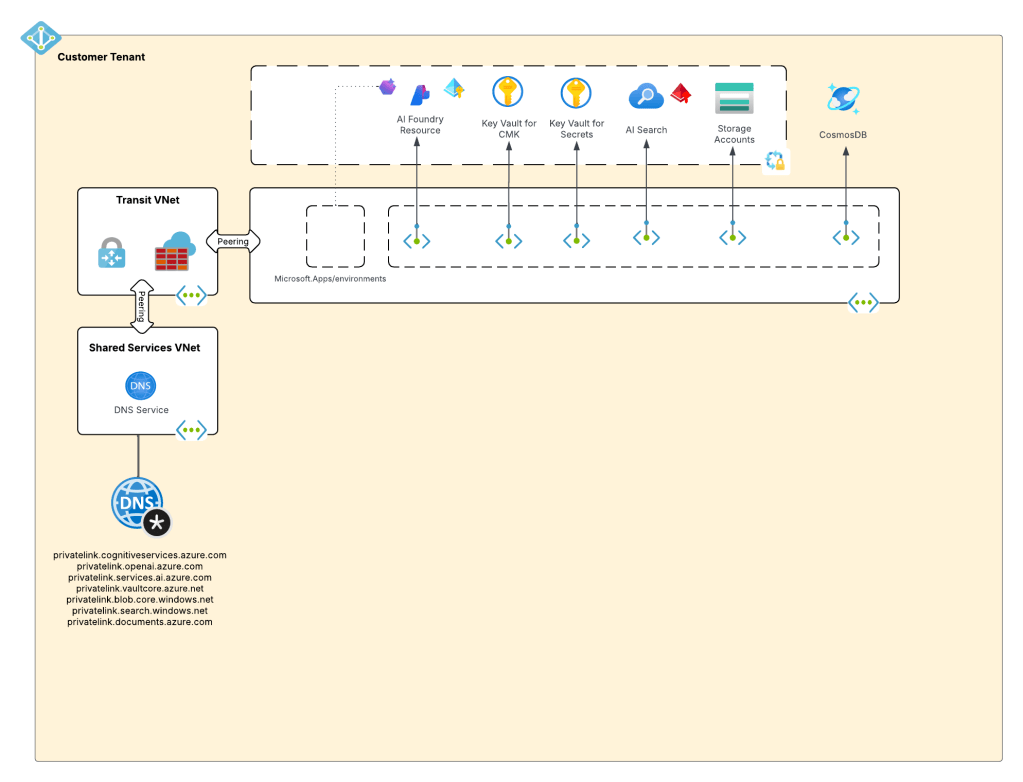
Ok, shit was complicated, I ain’t gonna lie. Given this complexity and feedback from the customers, Microsoft got ambitious and decided to further consolidate and simplify. This introduced the concept of a new top-level resource called Microsoft Foundry Accounts. In public documentation and conversation this may be referred to as Foundry Projects or Foundry Resources. Since this is my blog I’m going to use my term which is Microsoft Foundry Accounts. With Microsoft Foundry accounts, Microsoft collapsed the AI Services and Foundry Hubs into a single top level resource. Not only did they consolidate these two resources, they also shifted Foundry Hubs from the Azure Machine Learning resource provider into the Cognitive Services resource provider. This move consolidated the Cognitive Services resource provider as the “AI” resource provider in my brain. It resulted in a new architecture which often looks something like the below.
Microsoft Foundry Accounts common architecture
This is what I like to refer to as stage 3, which is the current stage we are in with Microsoft’s AI offerings. We will continue to see this stage evolve which more features build and integrated into the Microsoft Foundry Account. I wouldn’t be surprised at all to see other services collapse into it as just another endpoint to a the singular resource.
Why do you care?
You might be asking, “Matt, why the hell do I care about this?” The reason you should care is because there are many customers who jumped into these products at different stages. I run across a ton of customers still playing in Foundry Hubs with only a vague understanding that Foundry Hubs are an earlier stage and they should begin transitioning to stage 3. This evolution is also helpful to understand because it gives an idea of the direction Microsoft is taking its generative AI services, which is key to how you should be planning you future of these services within Azure.
I’ll dive into far more detail in future posts about stage 3. I’ll share some of my learnings (and my many pains), some reference architectures that I’ve seen work, how I’ve seen customers successfully secure and scale usage of Foundry Accounts.
For now, I leave you with this evolution diagram I like to share with customers. For me, it really helps land the stages and the evolution, what is old and what is new, and what services I need to think about focusing on and which I should think about migrating off of.
Foundry evolution
Well folks, that wraps it up. Your takeaways today are:
Assess which stage your implementation of generative AI is right now in Azure.
Begin plans to migrate to stage 3 if you haven’t already. Know that there will be gaps in functionality with Foundry Hubs and Foundry Accounts. A good example is no more prompt flow. There are others, but many will eventually land in Foundry project.



")