This is part of my series on Microsoft Entra ID:
- Entra ID – Deep Dive – The Basics – Part 1
- Entra ID – Deep Dive – Protocol Primer – Part 2
- Entra ID – Deep Dive – Entra ID Authentication – Part 3
Yeah… You read that right. I’m finally biting the bullet and doing a series on Entra ID. There are some cobwebs there, but once upon a time I was a half-baked “identity guy”. Nah, I’m not returning to that place, but I have had to visit it more frequently over the past few months. With the growing use of agents, identity has one again become of those things that apparently everyone is a so called “expert in”. I aint no expert, but I have been digging into the chatter around the implications of agents into the identity world. Given my employer, that has been spending some time in the Entra ID Agent Identity space.
Digging into that demanded I go back to some of the basics of Entra ID such as the purpose of an application registration versus a service principal and the request flow when authenticating a user to an application using OIDC (OpenID Connect) or executing an on-behalf-of flow in OAuth. I had conceptual knowledge of the above, but it was too ivory tower. I needed to eat the dog food and do it. After spending a few weeks reading through the documentation, reviewing captured requests and responses, reviewing RFCs, and poorly coding some applications to exercise on the concepts I figured it was time to brain dump what I learned before I get distracted with some new shiny widget and forget 60% of it.
So yeah… that’s where this series is coming from. Hopefully some folks out there draw some value out of it beyond serving as a refresher for my neural pathways.
With that rambling out of the way, let’s get to it.
WTF is Entra ID?
Many years ago when Microsoft first introduced Azure Active Directory my peers and I scratched our heads with this question. Given the name, the initial assumption was it was the Windows Active Directory “killer” (stop trying to make that happen, it aint gonna happen). That seems to have been a pretty common assumption given what I’ve heard from customers over the years as I sat in the vendor space and is likely why the name was shifted a few years back to Entra ID. Either that or marketing needed to justify their existence with another product rename.
If you want the professional explanation as to what Entra ID is you can read the public documentation and bask in the marketing mumbo jumbo. Since you’re here, you’re going to get the less fancy and quick and dirty Matt Felton explanation. My take is that Entra ID does a lot of shit, but at its core it is:
- An identity store for the identities of human and non-human security principals, their attributes, and their credentials.
- An authentication service which can act as an OAuth Authorization Server, OIDC identity provider, SAML IdP / SP, and even Kerberos / LDAP provider (gross)
It provides these core services to Microsoft’s cloud services such as M365, Azure, Dynamics 365, and whatever other clouds Microsoft has that I’m missing. It can be extended to provide these services to other applications by integrating with it via one of the supported protocols like we’ll see in further posts in this series.
Entra ID is divided into separate tenants which represent unique identity boundaries. Services for a given customer (such as an Azure subscription) are associated to an Entra ID tenant which acts as the identity boundary for those resources. Tenants can trust other tenants to facilitate cross tenant accessing of resources through features like Entra ID External ID.
The identity store piece of the Entra ID service is where users, groups, many types of service principals, applications, and device identities are stored. Similar to an LDAP (hell may be LDAP under the hood, who the hell knows) each of these objects has a schema with specific properties that are consumed for the other services Entra provides (as we’ll see later).
That should be enough context to give you a very general idea of what Entra ID is. Like I mentioned above, it does a lot of shit (conditional access, privileged identity management, etc) that isn’t relevant to the point of this series and that I’m not going to discuss. If you can hammer it in your head those two core functions, it will be enough to get you through this series.
Humans vs Non-Humans
Within Entra ID we have two primary objects that represent humans and non-humans. For humans we have the user identity. For non-humans we have service principals. Service principals come in many flavors including the base service principal (consider legacy), applications, managed identities, Agent Identity Blueprints, and Agent Identities (likely others I’m missing), Agent Users. The way I like to think about the many types of service principals (probably incorrect but I don’t care) is that the base service principal is the parent object class and things like managed identities, agent identity blueprints, and agent identities are children of that object class which look a bit different. Agent Users are a bit weird and I haven’t delved into them much, however, I like to think of it as a child of the base user object class.
The other object type that’s important to understand is the application object (typically referred to as the app registration). The application object is interesting (and can be confusing). It exists to represent a globally unique representation of an application. For a given application, you only ever have a single application object which exists in the tenant it was registered. What’s helped me is to think of the application object as the OAuth client registration. That’s probably not completely correct, but it helps ground you in its purpose. The application object can have a credential (secret, certificate, federated) which allows it to authenticate to Entra ID (think OAuth confidential client). It also contains information critical to OAuth such as the client id (appid), the audience (identifierUris), the OAuth scopes it supports (oauth2PermissionScopes), and redirectUris (when using interactive OAuth flows).
Below you’ll see an example of an application object for an application that is acting as a backend API to the demo solution I put together for this series.
Application Demo backend app for Entra authentication already exists and its id is 23f7d0f0-85e6-453a-b0bb-723b65ac7958{ "id": "23f7d0f0-85e6-453a-b0bb-723b65ac7958", "deletedDateTime": null, "appId": "22d2ff53-9442-404c-8da5-01c2e135532d", "applicationTemplateId": null, "disabledByMicrosoftStatus": null, "createdByAppId": "04b07795-8ddb-461a-bbee-02f9e1bf7b46", "createdDateTime": "2026-06-08T23:46:22Z", "displayName": "Demo backend app for Entra authentication", "description": "This app is used to demonstrate a backend API that uses the user's identity context to fetch a user's story'", "groupMembershipClaims": null, "identifierUris": [ "api://22d2ff53-9442-404c-8da5-01c2e135532d" ], "isDeviceOnlyAuthSupported": null, "isDisabled": null, "isFallbackPublicClient": false, "nativeAuthenticationApisEnabled": null, "notes": null, "publisherDomain": "XXXXXXXX.onmicrosoft.com", "serviceManagementReference": null, "signInAudience": "AzureADMultipleOrgs", "tags": [], "tokenEncryptionKeyId": null, "uniqueName": null, "samlMetadataUrl": null, "defaultRedirectUri": null, "certification": null, "optionalClaims": null, "servicePrincipalLockConfiguration": null, "requestSignatureVerification": null, "addIns": [], "api": { "acceptMappedClaims": null, "knownClientApplications": [], "requestedAccessTokenVersion": 2, "oauth2PermissionScopes": [ { "adminConsentDescription": "Allow the application to impersonate the signed-in user to access their user story.", "adminConsentDisplayName": "Impersonate user", "id": "00000000-0000-0000-0000-000000000001", "isEnabled": true, "type": "User", "userConsentDescription": "Allow the application to impersonate you to access your user story.", "userConsentDisplayName": "Impersonate user", "value": "user_impersonation" } ], "preAuthorizedApplications": [] }, "appRoles": [], "info": { "logoUrl": null, "marketingUrl": null, "privacyStatementUrl": null, "supportUrl": null, "termsOfServiceUrl": null }, "keyCredentials": [], "parentalControlSettings": { "countriesBlockedForMinors": [], "legalAgeGroupRule": "Allow" }, "passwordCredentials": [ { "customKeyIdentifier": null, "displayName": null, "endDateTime": "2028-06-08T23:46:45.7547438Z", "hint": "NnW", "keyId": "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXX", "secretText": null, "startDateTime": "2026-06-08T23:46:45.7547438Z" } ], "publicClient": { "redirectUris": [] }, "requiredResourceAccess": [ { "resourceAppId": "e406a681-f3d4-42a8-90b6-c2b029497af1", "resourceAccess": [ { "id": "03e0da56-190b-40ad-a80c-ea378c433f7f", "type": "Scope" } ] } ], "verifiedPublisher": { "displayName": null, "verifiedPublisherId": null, "addedDateTime": null }, "web": { "homePageUrl": null, "logoutUrl": null, "redirectUris": [], "implicitGrantSettings": { "enableAccessTokenIssuance": false, "enableIdTokenIssuance": false }, "redirectUriSettings": [] }, "spa": { "redirectUris": [] }}
Now comes the importance of the service principal. An application object will typically have an associated service principal (not much use without it) which acts as the security principal for the application in the given Entra ID tenant. Applications have one application object (or app registration) but many service principals (if it’s multi-tenant). Think of the service principal as the “stub” identity representing the application in the Entra ID tenant. Permissions are granted to the service principal and the application uses the service principal to exercise those permissions to do things such as querying the Microsoft Graph API.
If you build a multi-tenant application like I’ve done here, other Entra ID tenants can create a service principal for the application in their tenant allowing the application to possibly authenticate those users and access resources in that Entra ID tenant.
The official documentation likes to refer to the application object as the template for the application and the service principal as the security principal. I think that’s a pretty damn good single sentence explanation.
Below is an example of the service principal for the frontend application I built for this series. You can see the type of service principal (servicePrincipalType) in this scenario is application because this service principal has an associated application object (app registration).
{ "id": "ece073e5-744e-4d70-b79d-4887e1dd008f", "deletedDateTime": null, "accountEnabled": true, "alternativeNames": [], "appDisplayName": "Demo frontend app for Entra authentication", "appDescription": "This app is used to demonstrate a frontend application where a user authenticates using Entra ID authentication via OIDC", "appId": "afbd7539-a21f-4d11-93a3-490017032fb7", "applicationTemplateId": null, "appOwnerOrganizationId": "6c80de31-d5e4-4029-93e4-5a2b3c0e1299", "appRoleAssignmentRequired": false, "createdByAppId": "04b07795-8ddb-461a-bbee-02f9e1bf7b46", "createdDateTime": "2026-06-08T23:45:54Z", "description": null, "disabledByMicrosoftStatus": null, "displayName": "Demo frontend app for Entra authentication", "homepage": null, "isDisabled": null, "loginUrl": null, "logoutUrl": null, "notes": null, "notificationEmailAddresses": [], "preferredSingleSignOnMode": null, "preferredTokenSigningKeyThumbprint": null, "replyUrls": [ "http://localhost:8100/callback" ], "servicePrincipalNames": [ "afbd7539-a21f-4d11-93a3-490017032fb7" ], "servicePrincipalType": "Application", "signInAudience": "AzureADMultipleOrgs", "tags": [], "tokenEncryptionKeyId": null, "samlSingleSignOnSettings": null, "addIns": [], "appRoles": [], "info": { "logoUrl": null, "marketingUrl": null, "privacyStatementUrl": null, "supportUrl": null, "termsOfServiceUrl": null }, "keyCredentials": [], "oauth2PermissionScopes": [], "passwordCredentials": [], "resourceSpecificApplicationPermissions": [], "verifiedPublisher": { "displayName": null, "verifiedPublisherId": null, "addedDateTime": null }}
What are we going to build?
Now that you have the bare bones basics of Entra, you likely want to understand how an application would go about using it for authentication and authorization. While you might not be doing this now and it may not seem relevant, it will become very relevant to you if you begin building agents in Microsoft’s clouds through Microsoft Foundry, CoPilot Studio, or the 18 other random services Microsoft allows agents to be built. This will also be relevant to you if you’re going to consume Microsoft resources (such as Azure) from other clouds through an application or an agent. So yeah, you should understand what this looks like to do. The whole Entra ID Agent Identity feature builds on these foundational pieces.
To see these concepts in action I’m going to walk through a very simplistic solution with a frontend website and backend API in Python. The frontend website is built using the Flask Framework and the backend API is built with fastapi.
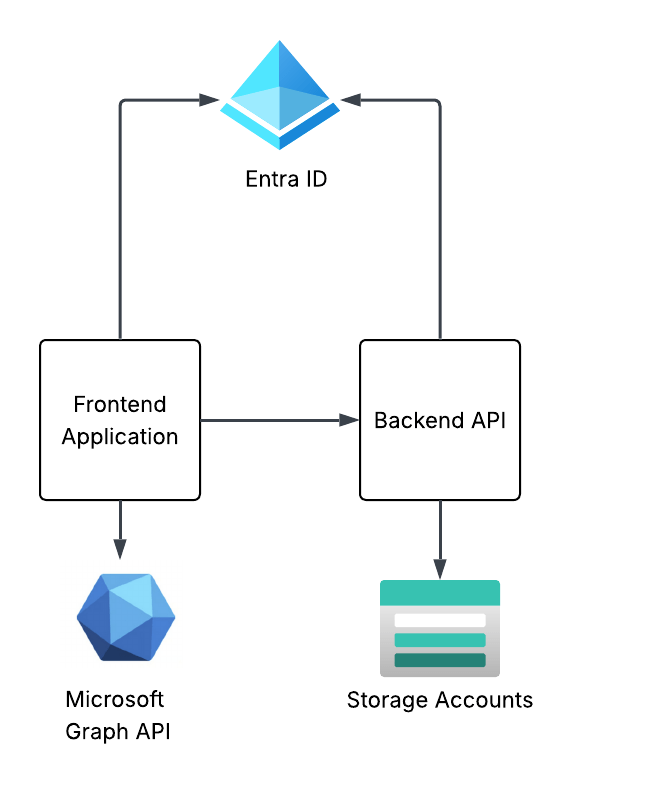
The frontend website will use Entra ID to authenticate the user and will be issued an OIDC id token to identify the user. The frontend will get some information from the user from the id token and access token it receives from Entra and will make additional calls to the Microsoft Graph API using the client credentials flow to grab other attributes of the user’s identity. I’ll also show how to include the user’s Entra ID group information in the id or access token and how to handle nested group membership.
The frontend will have a link on it to call the /story endpoint of the backend API. The story endpoint will pull a pre-built AI generated story about the user which has been uploaded toblob storage in an Azure Storage Account. The backend API will use the on-behalf-of flow to access the storage account as the user to pull the user’s specific story.
This will demonstrate some of the most common flows including authentication, OAuth client credentials flow, and OAuth on-behalf-of (or jwt bearer). I’ll show you how the id tokens and access tokens look in different scenarios pointing out the relevant claims and how they’re used upstream. I’ll even share some process flows so you understand what does what in a given flow.
My primary goal here is give you the basics so you can walk away with a more solid understanding of what’s happening under the hood and how Entra ID has decided to implement OIDC and OAuth. I can’t stress how helpful this will be for you once you start diving into the agent identity space (which I’ll be covering after this series).
Summing it up
Ok, so you know what you’re in for. This series is gonna be relatively deep in the weeds so bring your favorite caffeinated beverage for future posts. I’m doing everything direct with the REST APIs because I want to show you the gory details. No pretty SDKs for you. If you’ve had a “conceptual” idea of how this works without the implementation specifics (like I did before I went down this rabbit hole) this series should help to fill those gaps.
In the next post I’ll walk through setting up Entra for the frontend website, authenticating a user, and exploring the id token and access token. The post following that will walk through using the application’s identity context to get more information about the user from the Microsoft Graph API such as nested group membership, then I’ll finish up the series by walking through the on-behalf-of flow with the backend API to show you how to carry the user’s identity context through the application to the destination resource down the line.
See you next post!