
Hello fellow geeks!
Back in 2017 I did a series of posts on how to integrate Azure AD using the AWS app available in the Azure Marketplace with AWS IAM in order to use Azure AD as an identity provider for an AWS account. The series has remained quite popular over the past two years, largely because the integration has remained the same without much improvement. All of this changed last week when AWS released support for integration between Azure AD and AWS SSO.
The past integration between the two platforms functioned, but suffered from three primary challenges:
- The AWS app was designed to synchronize identity data between AWS and Azure AD for a single AWS account
- The SAML trust between Azure AD and an AWS account had to be established separately for each AWS account.
- The application manifest file used by the AWS app to establish a mapping of roles between Azure AD and synchronized AWS IAM roles had a limitation of 1200 which didn’t scale for organizations with a large AWS footprint.
To understand these challenges, I’m going to cover some very basic AWS concepts.
The most basic component an AWS presence is an AWS account. Like an Azure subscription, it represents a billing relationship, establishes limitations for services, and acts as an authorization boundary. Where it differs from an Azure subscription is that each AWS account has a separate identity and authentication boundary.
While multiple Azure subscriptions can be associated with a single instance of Azure AD to centralize identity and authentication, the same is not true for AWS. Each AWS account has its own instance of AWS IAM with its own security principals and no implicit trust with any other account.

Azure Subscription Identity vs AWS Account Identity
Since there is no implicit trust between accounts, that trust needs to be manually established by the customer. For example, if a customer wants bring their own identities using SAML, they need to establish a SAML trust with each AWS account.

SAML Trusts with each AWS Account
This is nice from a security perspective because you have a very clear security boundary that you can use effectively to manage blast radius. This is paramount in the cloud from a security standpoint. In fact, AWS best practice calls for separate accounts to mitigate risks to workloads of different risk profiles. A common pattern to align with this best practice is demonstrated in the AWS Landing Zone documentation. If you’re interested in a real life example of what happens when you don’t establish a good radius, I encourage you to read the cautionary tale of Code Spaces.
-
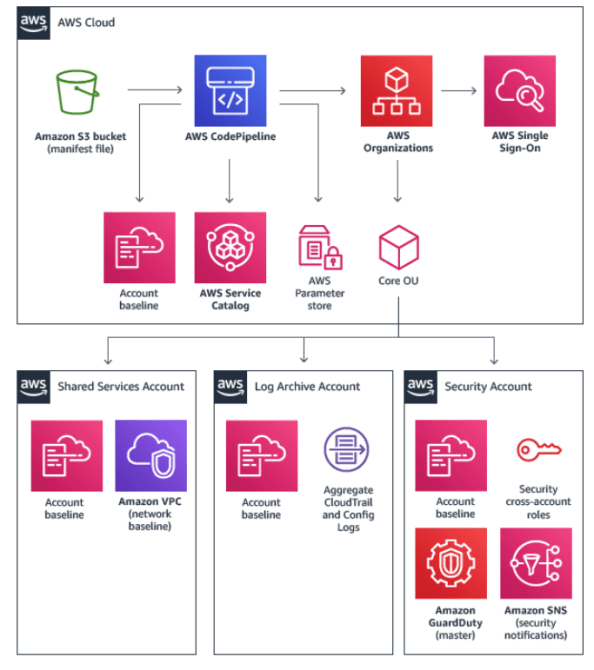
AWS Landing Zone
However, it doesn’t come without costs because each AWS IAM instance needs to be managed separately. Prior to the introduction of AWS SSO (which we’ll cover later), you as the customer would be on the hook for orchestrating the provisioning of security principals (IAM Users, groups, roles, and identity providers) in every account. Definitely doable, but organizations skilled at identity management are few and far between.
Now that you understand the importance of having multiple AWS accounts and that each AWS account has a separate instance of AWS IAM, we can circle back to the challenges of the past integration. The AWS App available in the Azure Marketplace has a few significant gaps
The app is designed to simplify the integration with AWS by providing the typical “wizard” type experience Microsoft so loves to provide. Plug in a few pieces of information and the SAML trust between Azure AD and your AWS account is established on the Azure AD end to support an identity provider initiated SAML flow. This process is explained in detail in my past blog series.
In addition to easing the SAML integration, it also provides a feature to synchronize AWS IAM roles from an AWS account to the application manifest file used by the AWS app. The challenges here are two-fold: one is the application manifest file has a relatively small limit of entries; the other is the synchronization process only supports a single AWS account. These two gaps make it unusable by most enterprises.

Azure Marketplace AWS Application Sync Process
Both Microsoft and AWS have put out workarounds to address the gaps. However, the workarounds require the customer to either develop or run custom code and additional processes and neither addresses the limitation of the application manifest. This lead to many organizations to stick with their on-premises security token service (AD FS, Ping, etc) or going with another 3rd party IDaaS (Okta, Centrify, etc). This caused them to miss out on the advanced features of Azure AD, some of which they were more than likely already paying for via the use of Office 365. These features include adaptive authentication, contextual authorization, and modern multi-factor authentication.
AWS recognized the challenge organizations were having managing AWS accounts at scale and began introducing services to help enterprises manage the ever growing AWS footprint. The first service was AWS Organizations. This service allowed enterprises to centralize some management operations, consolidate billing, and group accounts together for billing or security and compliance. For those of you from the Azure world, the concept is similar to the benefits of using Azure Management Groups and Azure Policy. This was a great start, but the platform still lacked a native solution for centralized identity management.
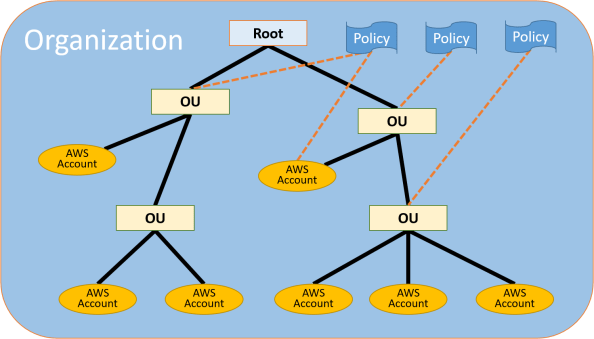
AWS Organization
At the end of 2017, AWS SSO was introduced. Through integration with AWS Organizations, AWS SSO has the ability to enumerate all of the AWS accounts associated with an Organization and act as a centralized identity, authentication, and authorization plane.
While the product had potential, at the time of its release it only supported scenarios where users and groups were created directly in the AWS SSO directory or were sourced from an AWS Managed AD or customer-managed AD using the LDAP connector. It lacked support for acting as a SAML service provider to a third-party identity provider. Since the service lacks the features of most major on-premises security token services and IDaaS providers, many organizations kept to the standard pattern of managing identity across their AWS accounts using their own solutions and processes.
Fast forward to last week and AWS announced two new features for AWS SSO. The first feature is that it can now act as a SAML service provider to Azure AD (YAY!). By federating directly with AWS SSO, there is no longer a requirement to federate Azure AD which each individual AWS account.
The second feature got me really excited and that was support for the System for Cross-domain Identity Management (SCIM) specification through the addition of SCIM endpoints. If you’re unfamiliar SCIM, it addresses a significant gap in IAM in the cloud world, and that is identity management. If you’ve ever integrated with any type of cloud service, you are more than likely aware of the pains of having to upload CSVs or install custom vendor connectors in order to provision security principals into a cloud identity store. SCIM seeks to solve that problem by providing a specification for a REST API that allows for management of the lifecycle of security principals.
Support for this feature, along with Azure AD’s longtime support for SCIM, allows Azure AD to handle the identity lifecycle management of the shadow identities in AWS SSO which represent Azure AD Users and Groups. This is an absolutely awesome feature of Azure AD and I’m thrilled to see that AWS is taking advantage of it.
Well folks, that will close out this entry in the series. Over the next few posts I’ll walk through what the integration and look behind the curtains a bit with my go to tool Fiddler.
See you next post!









