This is part of my series on GenAI Services in Azure:
- Azure OpenAI Service – Infra and Security Stuff
- Azure OpenAI Service – Authentication
- Azure OpenAI Service – Authorization
- Azure OpenAI Service – Logging
- Azure OpenAI Service – Azure API Management and Entra ID
- Azure OpenAI Service – Granular Chargebacks
- Azure OpenAI Service – Load Balancing
- Azure OpenAI Service – Blocking API Key Access
- Azure OpenAI Service – Securing Azure OpenAI Studio
- Azure OpenAI Service – Challenge of Logging Streaming ChatCompletions
- Azure OpenAI Service – How To Get Insights By Collecting Logging Data
- Azure OpenAI Service – How To Handle Rate Limiting
- Azure OpenAI Service – Tracking Token Usage with APIM
- Azure AI Studio – Chat Playground and APIM
- Azure OpenAI Service – Streaming ChatCompletions and Token Consumption Tracking
- Azure OpenAI Service – Load Testing
Hello again geeks. Yes, yet another Azure OpenAI Service (AOAI) post. I promise this one will be worth your time and you’ll be glad you didn’t have to bash your head against the keyboard like I did putting this one together.
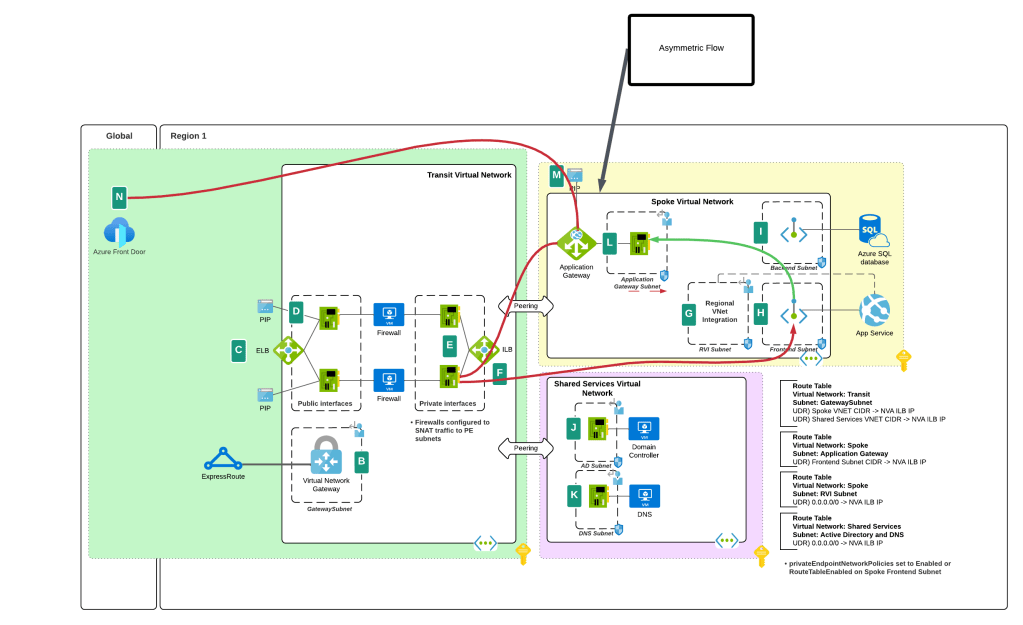
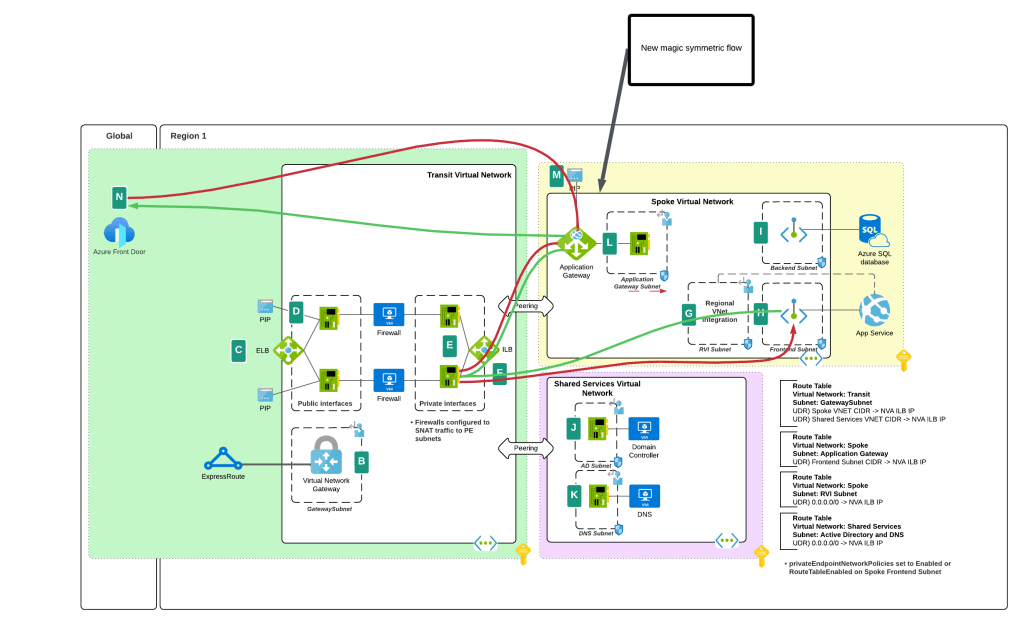
Last week I was chatting with a customer who has started down the journey of providing an enterprise-scale production-ready (Fancy words right? Practicing here so I can fake like I’m a real Microsoft employee) AOAI offering to their business units (BUs). What does a typical “enterprise-ready production-scale” deployment of AOAI look like? Well, it looks similar to what you see below. The goal of this type of deployment is to:
- Scale model quota by load balancing across multiple AOAI instances in different Azure regions and subscriptions
- Capture token usage for charge backs
- Ensuring everyone gets their fair share of the capacity by rate limiting based on token usage
- Capturing prompts and responses for regulatory requirements
- Caching prompts and responses to reduce costs
- Capturing additional metrics around usage of the service for optimizations and insights

As this customer got ready to open it up to the world, they were interested in doing some load testing on it to see how their Generative AI Gateway (Azure API Management in this case) and their backend AOAI instances would hold up to what they believed would be a production load. Some of my peers had done a similar exercise in the past with the Azure Load Testing service and Apache JMeter for a proof-of-concept. I was curious as to what this would like and how it would so I decided to throw something together, hence the post today.
So yeah, I’ve never touched the Azure Load Testing service nor have I touched JMeter more than once many many moons ago. The first step in the process was to read up on the Azure Load Testing service. This service is Microsoft’s cloud-based load testing service. It is essentially a service where MIcrosoft spins up a whole bunch of compute (engines) in Azure Batch which then runs a URL-test, Apache JMeter test, or Locust test. The compute simulates these tests (with the construct of a virtual user) as if it were a set of your users pounding away at the service.

Since most organizations have some familiarity with Apache JMeter I decided that I’d put together an Apache JMeter test. While there are a ton of JMeter examples for simple API calls, I had a hard time finding samples that involve acquiring an Entra ID access token for authentication to the API. While I could have grabbed an access token and tossed it into Azure Key Vault, I wanted to be a bit more fancy.
Creating the JMeter Test
After a bit of Googling I ended up coming across this blog post and this post which between the two I was able to get something working. I first created the thread group in JMeter and then added a Once Only Controller because I only wanted to obtain the access token once for each virtual user. From there, I added an HTTP Request sampler with the configuration below.

The parameters used in the authentication request are pulled from the environment variables object in the test. The environmental variables for the test are pulled from the Azure Load Testing service instance via a combination of environmental variables and secrets stored in Azure Key Vault (more on that later).

Once the request is complete and fetched the access token, I then used the JSON Extractor post-processor to extract the access token from the response and package into a new variable called access_token.

Ok sweet, got my access token. Next up I wanted to do a ChatCompletion against the AOAI services behind the API Management (APIM) instance. To do that I added another HTTP Request Sampler and populated it with the details below.

JMeter has a neat feature where you can pass contents of a CSV file to samplers to dynamically populate the values in the request. I wanted the ability to pass it multiple prompts so I added a config element for a CSV Data Set Config. Now there are a few quirks to using this config element with the Azure Load Testing service. One of those quirks is you do not want to specify any file path. Likely, when the engines are spun up, they’re getting the JMeter test and supporting CSVs dropped into the same directory so it’s not needed. Additionally, your CSV file can’t have header rows so you need to ensure you define the header roles in the variable names as is seen in the screenshot below.

Last but not least, I needed to ensure the HTTP Request passes the appropriate headers. I added the HTTP Header Manager config element and added the Content-Type and Authorization header which contained a reference to the access token I obtained in the prior HTTP Request.

At that point I had a JMeter test that should work within the Azure Load Testing service. The next step was to deploy the Azure Load Testing Service.
Azure Load Testing Service Instance
Deployment of the Azure Load Testing service instance was pretty straightforward. There really aren’t a ton of options for the actual service instance. The key things to note are that the Azure Load Testing service instances use managed identities to pull secrets or certificates from Azure Key Vault. This meant that along with the Azure Load Testing instance, I needed to deploy a user-assigned managed identity (my preference over system-assigned managed identities), an Azure Key Vault instance, secrets in the Azure Key Vault for a service principal that would be used in my tests, and set some Azure RBAC role assignments. The managed identity needs at least the Azure Key Vault Secrets User RBAC role on the Azure Key Vault instance (yes you should be using RBAC authorization model instead of the old access policies at this point).
What I deployed is highlighted in blue in the image below. I’ll cover the virtual network piece in the next section.

Azure Load Testing Test
At this point I got my JMeter test, my sample ChatCompletions, and Azure Load Testing service instance. Now it’s time to create the test within the Azure Load Testing service.
Creation of tests are a data plane activity and the ability to touch the data plane with IaC is very limited so I opted to use CLI (which has its own problems as we’ll see). Before I deployed the test, I had to create my test configuration. With the service you can define your test configuration in YAML. My test included the code below:
version: v0.1
test_id: genai_gateway_test
displayName: "GenAI Gateway Load Test"
description: "This will load test a Generative AI Gateway by sending ChatCompletions"
testType: JMX
testPlan: ./genai_gateway_test.jmx
engineInstances: 1
configurationFiles:
- './config/chat_completions.csv'
failureCriteria:
- percentage(error) > 80
autoStop:
errorPercentage: 80
timeWindow: 60
env:
- name: VIRTUAL_USERS
value: 10
- name: RAMP_UP
value: 1
- name: LOOP_COUNT
value: 1
- name: RESOURCE
value: 'https://cognitiveservices.azure.com'
# This is the fully-qualified domain name of your Generative AI Gateway
- name: OPENAI_ENDPOINT
value: mygenaigateway.company.com
- name: OPENAI_DEPLOYMENT_NAME
value: gpt-4o
- name: OPENAI_API_VERSION
value: 2024-04-01-preview
secrets:
# These are the credentials of the service principal that will be used to make the calls to the Generative AI Gateway
- name: TENANT_ID
value: https://mykeyvault.vault.azure.net/secrets/tenantid/38a3b814339944348710b216014f5acd
- name: CLIENT_ID
value: https://mykeyvault.vault.azure.net/secrets/clientid/94df372a3530469ea6e4b30064d9dbdc
- name: CLIENT_SECRET
value: https://mykeyvault.vault.azure.net/secrets/clientsecret/f8612911116f42fe8c1b77c53ca1b8de
# This property does not seem to work as of 10/2024
keyVaultReferenceIdentity: /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/myrg/providers/Microsoft.ManagedIdentity/userAssignedIdentities/myumi
subnetId: /subscriptions/00000000-0000-0000-0000-000000000000/resourceGroups/myrg/providers/Microsoft.Network/virtualNetworks/myvnet/subnets/mysubnet
publicIPDisabled: true
Yeah, there’s a lot there. There are a few areas I want to highlight.
The first area is the secrets section. Here I included the Key Vault secret references to the service principal credentials I have sitting in the Azure Key Vault. The keyVaultReferenceIdentity is supposed to set the test to use the managed identity you specify (this didn’t work for me as we’ll see later).
The next area is the subnetId and publicIPDisabled fields. The Azure Load Testing service has the ability to run tests where packets originate from a subnet in your virtual network. This allows you to hit services behind Private Endpoints or on-premises. Given that my APIM instance is deployed in internal mode, that was a requirement for me. I also wanted to control egress traffic from the test engines injected into my subnet. This is where I set the publicIPDisabled field to True. This causes all traffic from the test engines to flow through your preferred network path. Unfortunately, this includes both data plane and management plane traffic. You’ll need to ensure you allow required flows out your Internet egress point.
You can reference documentation for the other fields, but most are descriptive enough that you’ll get the picture.
Now it’s time to deploy the test. You can do this with az cli using the az load test create command.
Post Test Deployment
Done right? Ready to run the test? Nope, not yet.
There were a few properties I set within the YAML config that didn’t seem to take. This might be because the az load test is a preview command, I’m not really sure. Either way, the properties I noticed that did not stick were the keyVaultReferenceIdentity and splitAllCSVs properties. I explained the keyVaultReferenceIdentity property above. The splitAllCSVs property will take the contents of the CSV with your ChatCompletion and will distribute them across multiple engines (if you have multiple engines). If you have a large scale test, this is likely something you may want to do.
To ensure the test can pull the secrets needed to authenticate to Entra ID from Azure Key Vault, I needed to manually set it to use the service’s managed identity because the keyVaultReferenceIdentity property did not seem to work. To do that I logged into the Azure Portal and selected the newly created test GenAI Gateway Load Test and selected to modify the configuration of the test.

Under the parameters section towards the bottom, I was able to select the UMI I configured to be used by the Azure Load Testing service instance.

The other thing you can do with the Azure Load Testing service is pull metrics from supporting components (which the service refers to as server-side metrics). For this, I added the four AOAI instances I have sitting behind my APIM instance. I also needed to configure it to use the UMI associated with the service to pull the metrics (this UMI was granted permissions on the AOAI instances to pull the metrics in case I wanted to use any of them for metrics that drive how my test behaves).

Once those changes were complete I was good to go. If I was using multiple engines (which I’m wasn’t) and I wanted to split the completions in my CSV across engines, I would have to had to manually set the option for that (another one that doesn’t seem to work in the YAML in my testing). This option is located in the Test Plan section of the test configuration under the Split CSV evenly between Test engines option..
At this point you can begin running your tests.
Summing it up
While it takes a bit of doing, getting the Azure Load Testing service up and running was pretty easy. Because I’m a nice guy, I’ve uploaded sample code for everything I’ve done to this repository. Clone it and make it your own.
There are a ton more options within the Azure Load Testing Service beyond what I went over here so get out there and explore it. A few things to be aware of:
- Remember that for consumption-based services like Azure OpenAI, load testing could get expensive if you scale up your test large enough. Be ready for those costs.
- If you end up using the VNet injection option for your testing like I did, ensure you have proper networking in place. The compute that runs in your subnet needs to be able to make TCP connections to your Generative AI Gateway. It also needs to be able to resolve the name, so make sure you have DNS properly configured.
- You can lock down your Key Vault with the service firewall and the usage of Private Endpoints. In my testing, the Azure Load Testing service looks to be communicating over the Microsoft public IP address so ensure you have Allow Trusted Services option checked.