This is part of my series on GenAI Services in Azure:
- Azure OpenAI Service – Infra and Security Stuff
- Azure OpenAI Service – Authentication
- Azure OpenAI Service – Authorization
- Azure OpenAI Service – Logging
- Azure OpenAI Service – Azure API Management and Entra ID
- Azure OpenAI Service – Granular Chargebacks
- Azure OpenAI Service – Load Balancing
- Azure OpenAI Service – Blocking API Key Access
- Azure OpenAI Service – Securing Azure OpenAI Studio
- Azure OpenAI Service – Challenge of Logging Streaming ChatCompletions
- Azure OpenAI Service – How To Get Insights By Collecting Logging Data
- Azure OpenAI Service – How To Handle Rate Limiting
- Azure OpenAI Service – Tracking Token Usage with APIM
- Azure AI Studio – Chat Playground and APIM
- Azure OpenAI Service – Streaming ChatCompletions and Token Consumption Tracking
- Azure OpenAI Service – Load Testing
Hello again!
Today I’m back with another post focusing on AOAI (Azure OpenAI Service). My focus falls into two buckets: operations and security. For this post I’m going to cover a topic that falls into the operations bucket.
Last year I covered some of the challenges that arise when tracking token usage when the need arises to use streaming-based ChatCompletions. The challenges center around logging the prompt, response, and token usage. The guidance I provide in that prior post is unchanged for logging prompts and completions, but capturing token usage has gotten much easier. Before I dig into the details, I want to very briefly cover why you should care about and track token usage.
The whole “AI is the new electricity” statement isn’t all hype. Your business units are going to want to experiment with it, especially generative AI, to for optimizing business processes such as shaving time off how long it takes a call center rep to resolve a customer’s problem or automating a portion of what is now a manual limited value-added activity of highly paid employees to free them up to focus on activities that drive more business value. As an organization, you’re going to be charged with providing these services to the developers, data scientists, an AI engineers. The demand will be significant and you gotta figure out a scalable way to provide these services while satisfying security, performance, and availability requirements.
This will typically drive an architecture where capacity for generative AI is pooled and distributed to your business units a core service. Acting as a control point to ensure security, availability, and performance requirements can be met, the architectural concept of a Generative AI Gateway is introduced. This component usually translates to Azure API Management, 3rd party API Gateway, or custom developed solution with “generative ai-specific” functionality layered on top (load balancing, rate limiting based on token usage, token usage tracking, prompt and response logging, caching of prompts and responses to reduce costs and latency, etc).
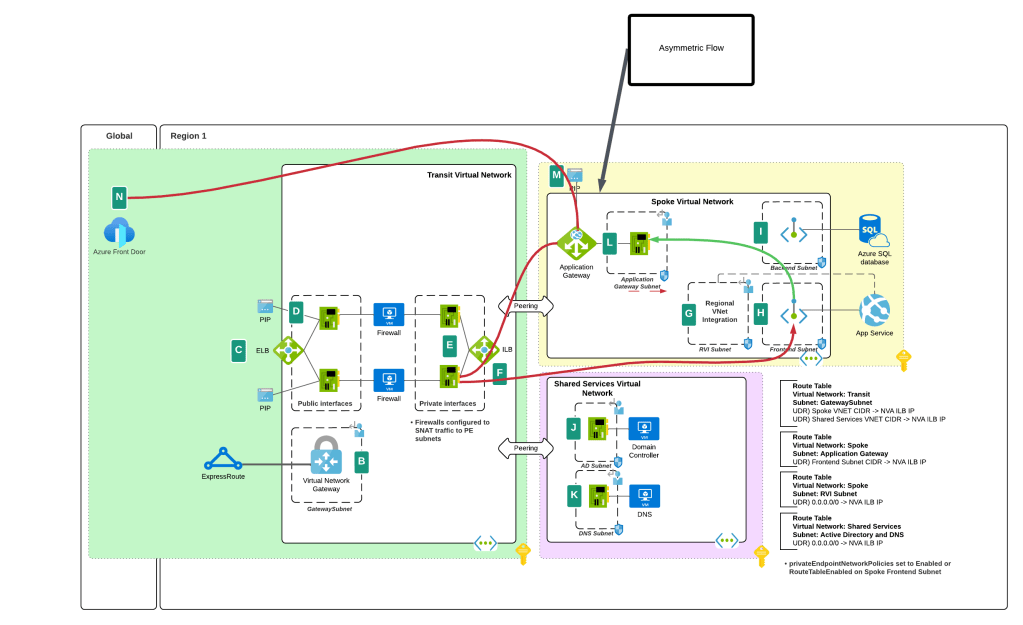
In Azure you might see a design like the image below where you’re distributing the requests across multiple AOAI instances spread across regions, geo-political boundaries, and subscriptions in order to maximize your quota (number of requests and tokens per model). When you have this type of architecture it’s important to get visibility into the token usage of each application for charge backs and to ensure everyone is getting their fair share of the capacity (i.e. rate limiting).

Now let’s align the token usage back to streaming ChatCompletions. With a non-streaming ChatCompletion the API automatically returns the number of prompt tokens, completion tokens, and total tokens that were consumed with the request. This information is easy to intercept at the Generative AI Gateway to use as an input for rate limiting or to pass on to some reporting system for charge backs on token usage.

When performing a streaming ChatCompletion the completion is returned in a series of server events (or chunks). Usage statistics were historically not provided in the response from the AOAI service to my understanding and experience. This forced the application developer or the owner of the Generative AI Gateway to incorporate some custom code using a Tokenizer like tiktoken to manually calculate the total number of tokens. An example of such a solution developed by one of my wonderful peers Shaun Callighan can be found here. This was one of the only (maybe the only?) to approach the problem at the time but sometimes resulted in slightly skewed results from what was estimated by the tokenizer to what the actual numbers were when processed by the AOAI service and billed to the customer.

Microsoft has made this easier with the introduction of the azure-openai-emit-token-metrics policy snippet for APIM (Azure API Management) which can emit token usage for both streaming and non-streaming completions (among other operations) to an App Insights instance. I talk through this at length in this post. However, at this time, it’s supported for a limited set of models and not every customer uses APIM. These customers have had to address the problem using a custom solution like I mentioned earlier.
Earlier this week I was mucking around with a simplistic ChatBot I’m building (FYI, Streamlit is an amazing framework to help build GUIs if you’re terrible at frontend design like I am) and I came across an additional parameter that can be passed when making a streaming ChatCompletion. You can pass an additional parameter called stream_options which will provide the token usage of the ChatCompletion in the the second to last chunk delivered back to the client. I’m not sure when this was introduced or how I missed it, but it removes the need to calculate this yourself with a tokenizer.
response = client.chat.completions.create(
model=deployment_name,
messages= [
{"role":"user",
"content": message}
],
max_tokens=200,
stream=True,
stream_options={
"include_usage": True
}
)Below you’ll see a sample response from a streaming ChatCompletion when including the stream_options property. In the chunk before the final chunk (there is a final check not visible in this image), the usage statistics are provided and can be extracted.

This provides a much better option than trying to calculate this yourself. I tested this with 3.5-turbo and 4o (both with text and images) and it gave me back the token usage as expected (I’m using API version 2024-02-01). I threw together some very simple (and if it’s coming from me it’s likely gonna be simple because my coding skills leave a lot to be desired) to capture these metrics and return them as part of the completion.
# Class to support completion and token usage
class ChatMessage:
def __init__(self, full_response, prompt_tokens, completion_tokens, total_tokens):
self.full_response = full_response
self.prompt_tokens = prompt_tokens
self.completion_tokens = completion_tokens
self.total_tokens = total_tokens
# Streaming chat completions
async def get_streaming_chat_completion(client, deployment_name, messages, max_tokens):
response = client.chat.completions.create(
model=deployment_name,
messages=messages,
max_tokens=max_tokens,
stream=True,
stream_options={
"include_usage": True
}
)
assistant_message = st.chat_message("assistant")
full_response = ""
with assistant_message:
message_placeholder = st.empty()
# Intialize token counts
t_tokens = 0
c_tokens = 0
p_tokens = 0
usage_dict = None
for chunk in response:
if chunk.usage:
usage_dict = chunk.usage
if p_tokens == 0:
p_tokens = usage_dict.prompt_tokens
c_tokens = usage_dict.completion_tokens
t_tokens = usage_dict.total_tokens
if hasattr(chunk, 'choices') and chunk.choices:
content = chunk.choices[0].delta.content
if content is not None:
full_response += content
message_placeholder.markdown(full_response)
if full_response == "":
full_response = "Sorry, I was unable to generate a response."
return ChatMessage(full_response, p_tokens, c_tokens, t_tokens)For those of using APIM as a Generative AI Gateway, you won’t have to worry about this for most of the OpenAI models offered through AOAI because the policy snippet I mentioned earlier will be improved to support additional models beyond what it supports today. For those of you using third-party gateways, this is likely relevant and may help to simplify your code and eliminate the discrepancies you see from calculating token usage yourself vs what you’re seeing displayed within the AOAI instance.
Well folks, this post was short and sweet. Hopefully this small tidbit of information helps a few folks out there who were going the tokenizer route. Any simplification these days is welcome!