It seems like it’s become a weekly occurrence to have sensitive data exposed due to poorly managed cloud services. Due to Amazon’s large market share with Amazon Web Services (AWS) many of these instances involve publicly-accessible Simple Storage Service (S3) buckets. In the last six months alone there were highly publicized incidents with FedEx and Verizon. While the cloud can be empowering, it can also be very dangerous when there is a lack of governance, visibility, and acceptance of the different security mindset cloud requires.
Organizations that have been in operation for many years have grown to be very reliant on the network boundary acting as the primary security boundary. As these organizations begin to move to a software defined data center model this traditional boundary quickly becomes less and less effective. Unfortunately for these organizations this, in combination with a lack of sufficient understanding of cloud, gives rise to mistakes like sensitive data being exposed.
One way in which an organization can protect itself is to leverage technologies such as cloud access security brokers (cloud security gateways if you’re Forrester reader) to help monitor and control data as it travels between on-premises and the cloud. If you’re unfamiliar with the concept of a CASB, I covered it in a previous entry and included a link to an article which provides a great overview.
Microsoft has its own CASB offering called Microsoft Cloud App Security (CAS). It’s offered as part of Microsoft’s Enterprise Mobility and Security (EMS) E5/A5 subscription. Over the past several months multiple connectors to third party software-as-a-service (SaaS) providers have been introduced, including one for AWS. The capabilities with AWS are limited at this point to pulling administrative logs and user information but it shows promise.
As per usual, Microsoft provides an integration guide which is detailed in button pushing, but not so much in concepts and technical details as to what is happening behind the scenes. Since the Azure AD and AWS blog series has attracted so many views, I thought it would be fun and informative to do an entry for how Cloud App Security can be used with AWS.
I’m not in the habit of re-creating documentation so I’ll be referencing the Microsoft integration guide throughout the post.
The first thing that needs doing is the creation of a security principal in AWS Identity and Access Management (AWS IAM) that will be used by your tenant’s instance of CAS to connect to resources in your AWS account. The first four steps are straightforward but step 5 could a bit of an explanation.
 Here we’re creating a custom IAM policy for the security principal granting it a number of permissions within the AWS account. IAM policies are sets of permissions which are attached to a human or non-human identity or AWS resource and are evaluated when a call to the resource is made. In the traditional on-premises world, you can think of it as something somewhat similar to a set of NTFS file permissions. When the policy pictured above is created the security principal is granted a set of permissions across all instances of CloudTrail, CloudWatch, and IAM within the account.
Here we’re creating a custom IAM policy for the security principal granting it a number of permissions within the AWS account. IAM policies are sets of permissions which are attached to a human or non-human identity or AWS resource and are evaluated when a call to the resource is made. In the traditional on-premises world, you can think of it as something somewhat similar to a set of NTFS file permissions. When the policy pictured above is created the security principal is granted a set of permissions across all instances of CloudTrail, CloudWatch, and IAM within the account.
If you’re unfamiliar with AWS services, CloudTrail is a service which audits the API calls made to AWS resources. Some of the information included in the events include the action taken, the resource the action was taken upon, the security principal that made the action, the date time, and source IP address of the security principal who performed the action. The CloudWatch service allows for monitoring of metrics and optionally triggering events based upon metrics reaching specific thresholds. The IAM service is AWS’s identity store for the cloud management layer.
Now that we have a basic understanding of the services, let’s look at the permissions Microsoft is requiring for CAS to do its thing. The CloudTrail permissions of DescribeTrails, LookupEvents, and GetTrailStatus allow CAS to query for all trails enabled on an AWS account (CloudTrail is enabled by default on all AWS resources), lookup events in a trail, and get information about the trail such as start and stop logging times. The CloudWatch permissions of Describe* and Get* are fancy ways of asking for READ permissions on CloudWatch resources. These permissions include describe-alarms-history, describe alarms, describe-alarms-for-metric, get-dashboard, and get-metric-statistics. The IAM permissions are similar to what’s being asked for in CloudWatch, basically asking for full read.
Step number 11 instructs us to create a new CloudTrail trail. AWS by default audits all events across all resources and stores them for 90 days. Trails enable you to direct events captured by CloudTrail to an S3 bucket for archiving, analysis, and responding to events.

The trail created is consumed by CAS to read the information captured via CloudTrail. The permissions requested above become a bit more clear now that we see CAS is requesting read access for all trails across an account for monitoring goodness. I’m unclear as to why CAS is asking for read for CloudWatch alarms unless it has some integration in that it monitors and reports on alarms configured for an AWS account. The IAM read permissions are required so it can pull user information it can use for the User Groups capability.
After the security principal is created and a sample trail is setup, it’s time to configure the connector for CAS. Steps 12 – 15 walk through the process. When it is complete AWS now shows as a connected app.

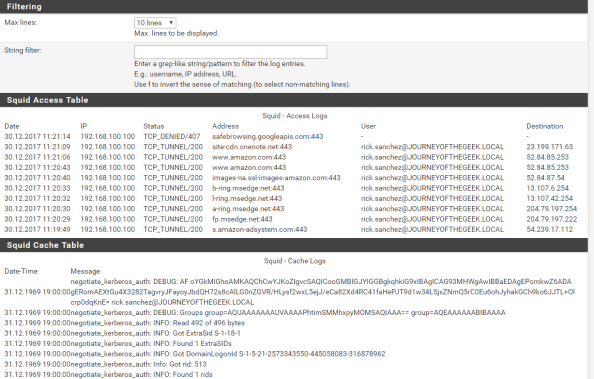
After a few hours data will start to trickle in from AWS. Navigating to the Users and Accounts section shows all of the accounts found in the IAM instance for my AWS account. Envision this as your one stop shop for identifying all of the user accounts across your many cloud services. A single pane of glass to identity across SaaS.

On the Activity Log I see all of the API activities captured by CloudTrail. If I wanted to capture more audit information, I can enable CloudTrail for the relevant resource and point it to the trail I configured for CAS. I haven’t tested what CAS does with multiple trails, but based upon the permissions we configured when we setup the security principal, it should technically be able to pull from any trail we create.

Since the CAS and AWS integration is limited to pulling logging information, lets walk through an example of how we could use the data. Take an example where an organization has a policy that the AWS root user should not be used for administrative activities due to the level of access the account gets by default. The organization creates AWS IAM users accounts for each of its administrators who administer the cloud management layer. In this scenario we can create a new policy in CAS to detect and alert on instances where the AWS root user is used.
First we navigate to the Policies page under the Control section of CAS.

On the Policies page we’re going to choose to create a new policy settings in the image below. We’ll designate this as a high severity privileged account alert. We’re interested in knowing anytime the account is used so we choose the Single Activity option.
We’ll pretend we were smart users of CAS and let it collect data for a few weeks to get a sampling of the types of events which are captured and to give us some data to analyze. We also went the extra mile and leveraged the ability of CAS to pull in user information from AWS IAM such that we can choose the appropriate users from the drop-down menus.
Since this is a demo and my AWS lab has a lot of activity by the root account we’re going to limit our alerts to the creation of new AWS IAM users. To do that we set our filter to look for an Activity type equal to Create user. Our main goal is to capture usage of the root account so we add another filter rule that searches for a User with the name equal to aws root user where it is the actor in an event.

Finally we configure the alert to send an email to the administrator when the event occurs. The governance capabilities don’t come into play in this use case.

Next we jump back to AWS and create a new AWS IAM user named testuser1. A few minutes after the user is created we see the event appearing in CloudTrail.

After a few minutes, CAS generates and alert and I receive an email seen in the image below. I’m given information as to the activity, the app, the date and time it was performed, and the client’s IP address.

If I bounce back to CAS I see one new Alert. Navigating to the alert I’m able to dismiss it, adjust the policy that generated it, or resolve it and add some notes to the resolution.

I also have the option to dig deeper to see some of the patterns of the user’s behavior or the pattern of the behaviors from a specific IP address as seen below.


All this information is great, but what can we do with it? In this example, it delivers visibility into the administrative activities occurring at the AWS cloud management layer by centralizing the data into a single repository which I can then send other data such as O365 activity, Box, SalesForces, etc. By centralizing the information I can begin doing some behavioral analytics to develop standard patterns of behavior of my user base. Understanding standard behavior patterns is key to being ahead of the bad guys whether they be insiders or outsiders. I can search for deviations from standard patterns to detect a threat before it becomes too widespread. I can also be proactive about putting alerts and enforcement (available for other app connectors in CAS but not AWS at this time) to stop the behavior before the threat is realized. If I supplemented this data with log information from my on-premises proxy via Cloud App Discovery, I get an even larger sampling improving the quality of the data as well as giving me insight into shadow IT. Pulling those “shadow” cloud solutions into the light allow me to ensure the usage of the services complies with organizational policies and opens up the opportunity of reducing costs by eliminating redundant services.
Microsoft categorizes the capabilities that help realize these benefits as the Discover and Investigate capabilities of CAS. The solution also offers a growing number of enforcement mechanisms (Microsoft categorized these enforcement mechanisms as Control) which add a whole other layer of power behind the solution. Due to the limited integration with AWS I can’t demo those capabilities with this post. I’ll cover those in a future post.
I hope this post helped you better understand the value that CASB/CSGs like Microsoft’s Cloud App Security can bring to the table. While the product is still very new and a bit sparse on support with 3rd party applications, the list is growing every day. I predict the capabilities provided by technology such as Microsoft’s Cloud App Security will be as standard to IT as a firewall in the years to come. If you’re already in Office 365 you should be ensuring you integrate these capabilities into your arsenal to understand the value they can bring to your business.
Thanks and have a wonderful week!




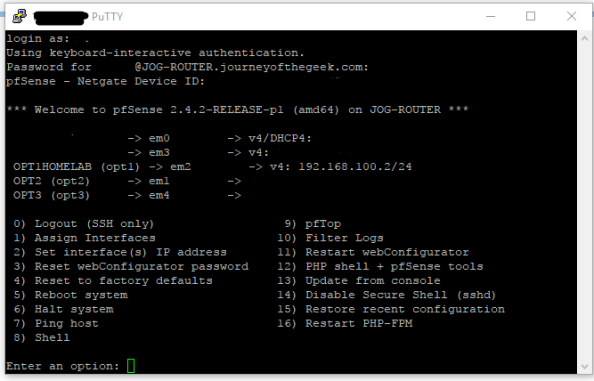 You want to hit the command shell so choose option 8 and you will be dropped into the shell.
You want to hit the command shell so choose option 8 and you will be dropped into the shell.