Over the past few weeks I’ve been diving into the relatively new Azure product Azure Virtual Network Manager (AVNM). AVNM was first introduced back in late 2021 with the connectivity feature and security admin rule feature. In the past year both features have begun to trickle into general availability in some regions. I was interested in the Security Admin Rules feature so I did my usual thing and began to read through all the documentation and experiment with the service. I’ll be covering Security Admin Rules in another post. In this short post I will be focusing on how you onboard virtual networks to the connectivity and security admin rule features.
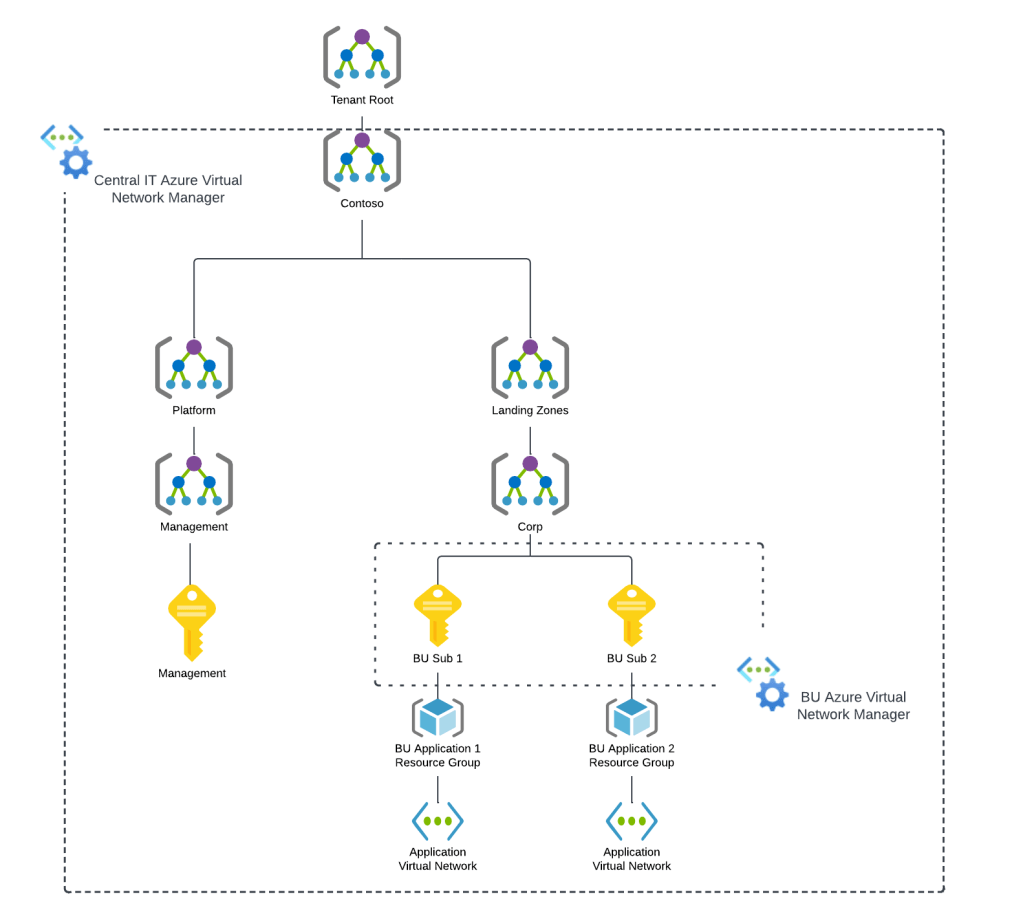
When an AVNM instance is created, it is assigned a scope of what it can manage. This can subscriptions added individually or it can be all subscriptions under a specific management group. A given scope can only have one AVNM instance assigned to it.
Azure Virtual network Manager Sample Architecture
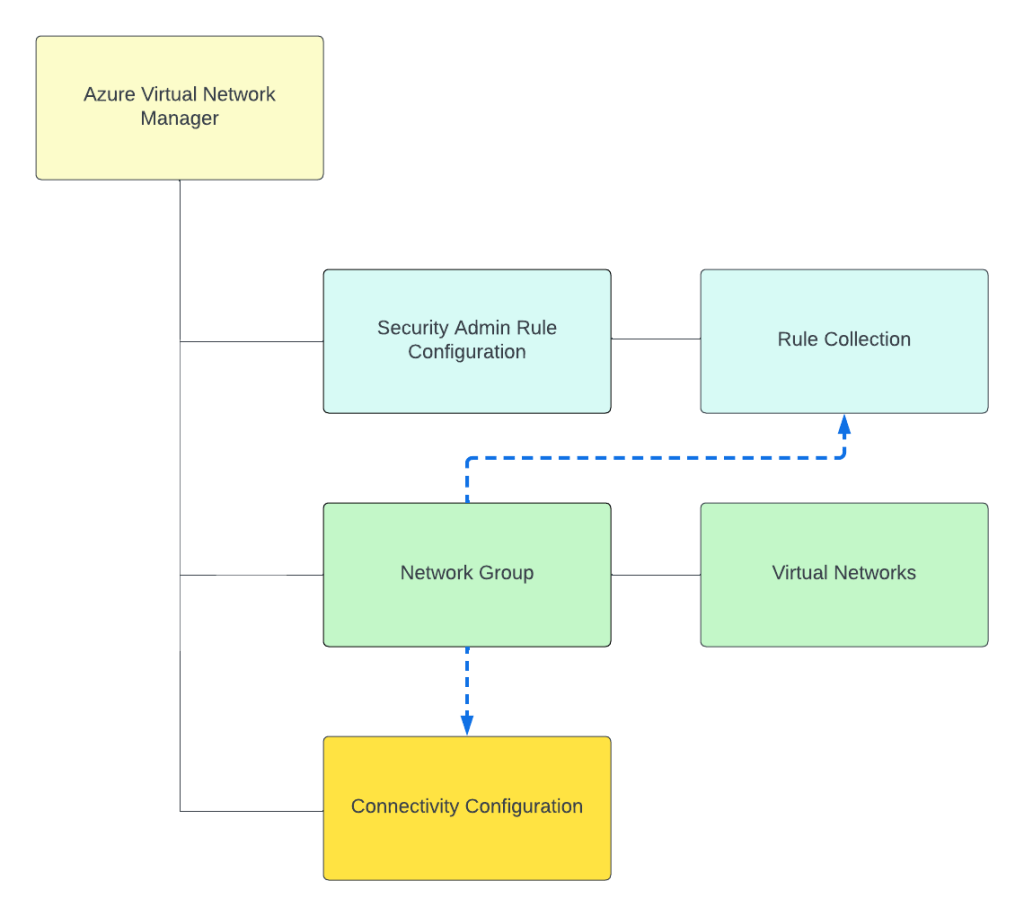
Today, under the assigned scope, AVNM can manage how virtual networks are connected to each other with the connectivity feature and what traffic is allowed or denied within the virtual network with the security admin rules feature superseding Network Security Groups. Within an AVNM instance you group virtual networks under the managed scope into a construct called a Network Group. Network Groups are then associated to either a connectivity or security admin rule configuration as seen below.
Network groups can contain multiple virtual networks and virtual networks can be members of multiple Network Groups. Virtual networks can be added to a Network Group manually or dynamically through Azure Policy. The rest of this post will focus on dynamic membership and some of the interesting properties of the Azure Policy definitions.
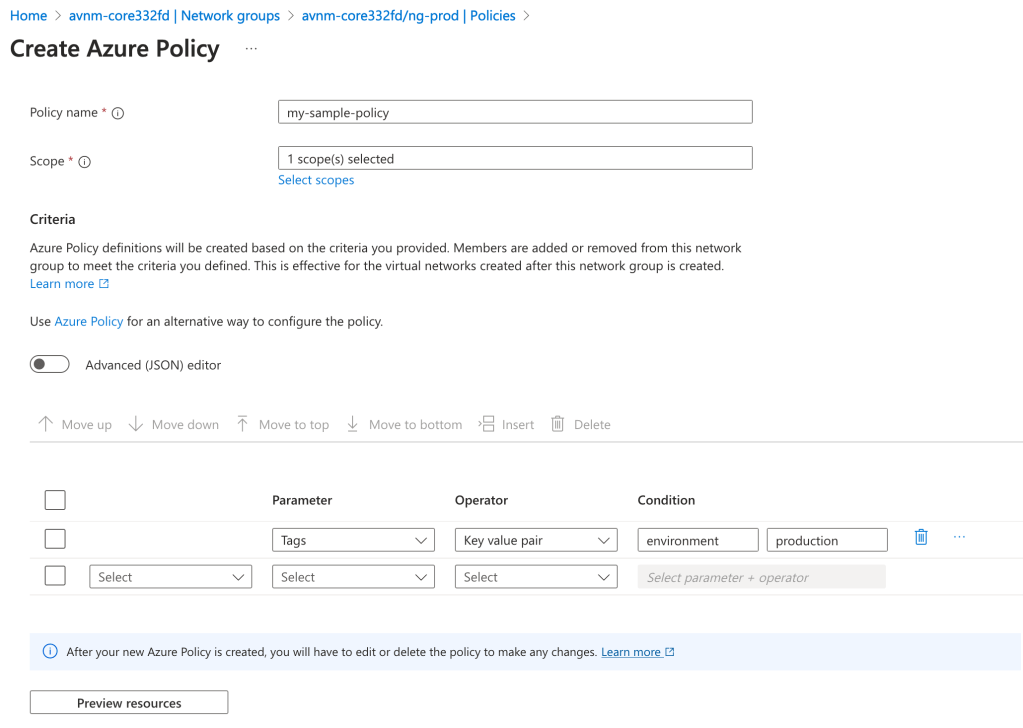
Before I dive into the policy definition I want to call out a neat feature the Product Group built into the solution. When accessing an AVNM instance from the Azure Portal there is a handy GUI-based tool included that can be used to graphically build the conditions on which virtual networks will be members of the Network Group. In the background, this tool builds out the Azure Policy definition and creates the assignment at the scopes you specify. This is one of the only products I’ve come across within Azure that assists the customer in building out an Azure Policy for the service. Great job by the product group!
Azure Policy builder to onboard virtual networks into a Network Group in Azure Virtual Network Manager
With the settings pictured above, I’m creating an Azure Policy to onboard all virtual networks tagged (there are a number of parameters and operators combinations you can use besides tags) with the key of environment and value of production under the specified scope to the Network Group. The policy will look something like this:
I’ve bolded the two properties I want you to key in on. The first property is the mode property. If you’ve written a custom Azure Policy or examined built-in policies you will likely be used to that property being set to either all or indexed. Here you will see it is set to Microsoft.Network.Data. This is one of the new resource provider modes that has been introduced which extends Azure Policy’s functionality. The other interesting property is the effect property. Again, you will likely be used to this being audit, deny, deployIfNotExists, etc. Instead, it is populated with a value of addToNetworkGroup. Both of these properties are specific to AVNM’s feature for dynamic members into its Network Groups.
Being the geek I am, I decided to try writing my own custom Azure Policy definition which would parameterize the the tag key, value, and resource id of the Network Group. Interestingly, you’re blocked from parameterizing the Network Group id due to a regex filter that has been put in. This regex filter validates that the Network Group id looks like an id and will reject if you try to do it as a parameter. I plan on submitting some feedback requesting this regex filter be removed which would allow for this to be fully parameterized. As of now, it looks like you’ll need an Azure Policy definition for each Network Group where you’re using dynamic membership.
Error message when parameterizing Network Group resource id
Once you create your Azure Policy definition and create the assignment, at the next policy evaluation the matching virtual networks will be added into the Network Group as dynamic members. The feature works exactly as described and is incredibly handy in quickly and efficiently onboarding new and existing virtual networks to a specific Network Group to apply a connectivity or security admin rule configuration.
Well folks that’s it for this short blog post. I found the dynamic membership and new Azure Policy properties interesting enough to warrant their own post. I’ve added an example working parameterized Azure Policy definition to my custom Azure Policy GitHub repo if you’re interested in messing around with it yourself.
Expect more posts to come on Azure Virtual Network Manager. Have a great night!
2/11/2025 Update – This action is now captured in the Entra ID Audit Logs! I’d recommend putting an alert in ASAP to track this moving forward.
Hello fellow geek!
Today I’m going to cover a topic that isn’t well understood in the Azure community and can present significant risk to your Azure estate. Sit back, grab your Friday morning coffee, and prepare to learn about the “real” root management group.
Microsoft made an interesting identity-based choice when architecting Azure. That choice was to have all Azure subscriptions share a common identity management plane in what we have known as Azure AD (Azure Active Directory) and which has recently been renamed Entra ID. The shared identity management plane in Azure creates a single authority for identity data and authentication while maintaining separate authorization boundaries between Azure subscriptions. This concept may differ for those of you coming from AWS (Amazon Web Services) where every AWS account has a unique identity management plane that has its own identity data store, authentication boundary, and authorization boundary. Microsoft’s decision comes with benefits and considerations.
The atomic unit for resources in Microsoft Azure is the Azure subscription which acts as an authorization boundary, limits boundary, and compliance boundary. Each Azure subscription can be associated to a single Entra ID tenant. Once a subscription is associated to an Entra ID tenant the subscription will use tenant as a source of identity data and authentication provider. This dependency on Entra ID creates an interesting security risk around authorization.
Before I dive into the details of this, let me briefly explain the concept of management groups. A management group in Azure is a logical container for Azure Subscriptions which allow for you to enforce configuration “how a resource looks” (Azure Policy) and authorization “what a user can do” (Azure RBAC) across one or more subscriptions. Prior to management groups, these things had to be managed at the individual subscription level or below (resource group or individual resource). Every subscription added to an Entra ID tenant exists under the Tenant Root Management Group by default, but this can be changed. Customers can can create additional management groups underneath the Tenant Root Management Group as per their needs (great guidance on this here).
If you’ve used Azure for any length of time the above is likely all review for you. However, as Yoda said, “there is another”. Above the Tenant Root Management Group exists another management group called root or “/”. As seen in the visual below, the root management group is the glue that sticks Entra ID authorization to Azure authorization together. Let’s dig into how this works.
Entra ID and Microsoft Azure Authorization
In Entra ID there is a role called Global Administrator. For those of you unfamiliar with this role, it is the god role of Entra ID and all services associated with an Entra ID tenant such as M365 and, yes, Azure. Holding this role in Entra ID does not give you permissions in Azure, but there is a path to give yourself permissions and become the god of your Azure estate.
Users who hold the Global Administrator have the ability to grant themselves access on the root “/” management group. They can do this through an option in the Entra ID blade of the Azure Portal called Access Management for Azure Resources or Elevate Access. This is also available via the Azure REST API using the elevateAccess endpoint. The value of this toggle switch shown in the Portal is the value for the current user context (user logged into the Portal). You cannot view this toggle switch for other users, but we can tell if it’s been toggled on as I will show later.
Option for Global Admins to assert control over Azure
When a Global Administrator toggles this option either through the Portal or through the REST API an Azure RBAC Role Assignment for the User Access Administrator is created at the root “/” management group.
User Access Administrator role assignment as result of global administrator elevate access
The User Access Administrator is a highly privileged role granting the user full permissions over the Microsoft.Authorization resource provider (as seen below). These permissions allow the user to create additional role assignments on for any Azure RBAC Role on any Azure management, subscription, resource group, or resource within the Entra ID tenant. Yes… yikes.
As I mentioned earlier, the Portal will only show you the value of the toggle switch for the ElevateAccess feature for the currently logged in user. You may now be thinking “How the heck can I enforce this if I can’t view it in the Portal?”. The good news is this toggle seems to be some backend orchestration where the platform checks whether the user has the User Access Administrator RBAC Role Assignment on the root “/” management group. This means you don’t need to care about that visual toggle switch, you only need to care about the actual permission. You can list out the the users that have the role assignment at root using the cli command below.
az role assignment list --scope "/" --query "[?roleDefinitionName=='User Access Administrator'].{Username:principalName, ObjectId:objectId}" --output table
Awesome, so you know who has it. Why should you care? Listen, I gonna be nice and assume you’re asking this because it’s a Friday and your brain is fried. The reason you should care is this gives your users who have access to the Entra ID Global Administrators Role the ability to make themselves god of your Azure estate. This includes owners over the resources for management plane operations which can, in almost every instance, lead to owner of the data contained within the resources within the data plane. You SHOULD NOT have a role assignment for User Access Administrator on the root “/” management group. There a few instances where you need this permission temporarily to grant other permissions, but I will cover that at the end of this post. For now, know that if you have that permission there you shouldn’t.
In most enterprises there is a separate team managing Entra ID from the team managing Azure in order to maintain separation of duties. Access to the Global Administrator role opens up the risk for the user to assert access and control over data that is outside of their roles and responsibilities. While there is no way to stop this from happening, you should be monitoring for when it occurs. So how might you do this?
If you’re used Azure, you should be familiar with Azure Activity Logs. The Activity Logs contain log entries for create, update, and delete operations on the Azure management plane. Activity Logs exist at a number of scopes including Subscription, Management Group, and Directory. While Subscription and Management Group Activity Logs supports integration with Azure Monitor Diagnostic Logs, Directory Activity Logs do not and those are the logs new role assignments to the root “/” management group are recorded in. This means you need to write custom code to manually pull down those logs via the REST API in order to capture and alert on them in your favorite SIEM. Yuck right? Well there is an easier way to alert on this.
Directory-level Azure Activity Logs
A while back Microsoft introduced support for Azure Monitor to make log queries against the Azure Resource Graph. I’m not going to do a deep dive into ARG (Azure Resource Graph). All you need to know for the purpose of this post is it’s a service you can tap into to pull down information about Azure resources, including role assignments.
Let me walk through how this works.
I can issue an Kusto query through Azure Monitor to query ARG to see what role assignments for User Access Administrator exist on the root “/” management group using the query below (note this will require you have appropriate read permissions at root “/”).
arg("").AuthorizationResources
| where properties.scope == "/"
| where properties.roleDefinitionId == "/providers/Microsoft.Authorization/RoleDefinitions/18d7d88d-d35e-4fb5-a5c3-7773c20a72d9"
This Kusto query will query the ARG authorizationresources category for any role assignments on the root “/” management group that have the role definition id for User Access Administrator. Each resulting log entry denotes a role assignment on root. Here we can see I have two role assignments on the root for User Access Administrator. Bad Matt.
Query to pull role assignments for User Access Administrator on root “/” management group
Back in October 2023 Microsoft introduced into public preview support to create Azure Alerts for Azure Monitor Log queries against ARG. This means you can create an Azure Alert based on this custom log query. If there is a role assignment for User Access Administrator on the root “/” management group, an alert will be fired. Let me walk through the setup of that alert, because it’s a little bit funky.
Select the option to create a new Alert Rule. In the scope section you can select a subscription. If you are using a similar subscription design as to the Azure Cloud Adoption Framework, selecting the Management subscription would be a good choice. I don’t believe the choice matters much because the alert is on the root management group and not a resource within a subscription.
On the condition screen you will choose the Custom log search option for the Signal name. The query you’ll put in there is below.
arg("").AuthorizationResources
| where properties.scope == "/"
| where properties.roleDefinitionId == "/providers/Microsoft.Authorization/RoleDefinitions/18d7d88d-d35e-4fb5-a5c3-7773c20a72d9"
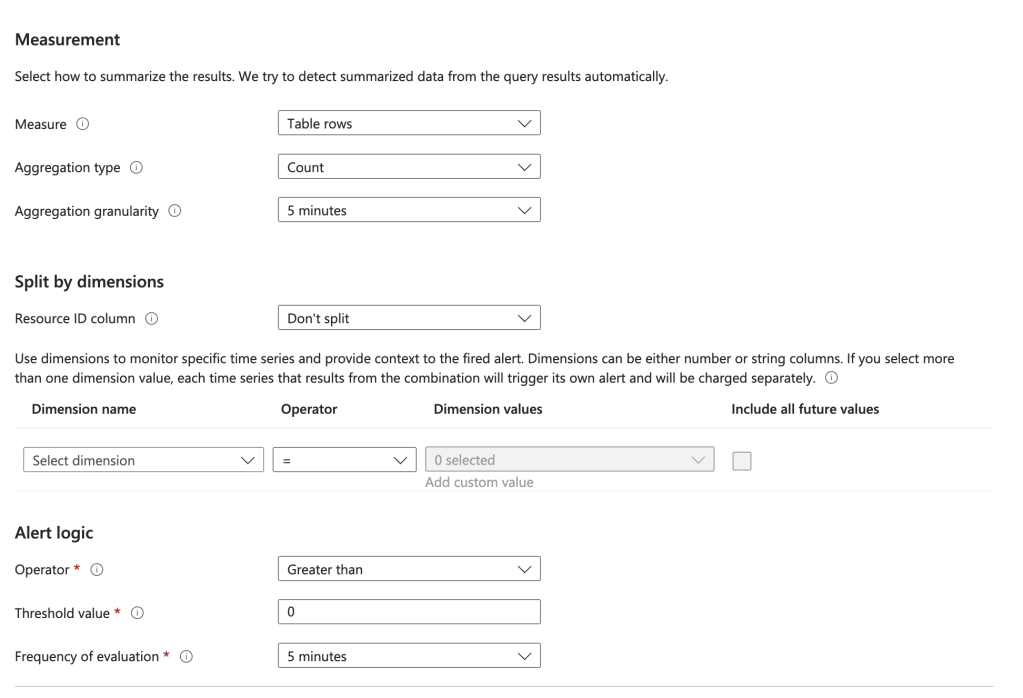
You will will also need to configure the measurements. You can use the settings I have below or customize it to your liking.
Measurements for alert
On the Actions screen choose Select action groups and select the action group you configured before.
On the Details screen you can set the severity to whatever you want. I’d recommend 0 since this is a significant escalation of privilege. You will also need to configure the alert with a managed identity. It will need an identity to authenticate and be authorized to ARG. Choose whichever managed identity type makes sense for your organization.
Adding a managed identity to the alert
Add whatever tags you want on the next screen and create the alert.
Done right? No, we now need to give the managed identity permissions on the root management group to read the role assignments.
I promised earlier I’d tell you the instance where you need to use this elevation. The are very few instances where you need to do this. One instance is when you are first building out your management group structure. In that scenario, no one has permission over the root or tenant root management group so no one can create new management groups. You will need to elevate a user with Global Administrator to the User Access Administrator role on the root “/” in that situation so that use can then grant another user account owned by the Azure team (ideally non-human, but vaulted is good too) User Access Administrator on the Tenant Root Management Group. When complete, the Global Administrator should toggle that switch back to off to remove the RBAC role assignment. This Microsoft article explains a few other scenarios you may need to temporary grant this role to grant permissions at the root “/”.
Now back to setting up the alert rule. Next up you need to grant the managed identity you assigned to the alert rule the permission at the root “/” management group so it can query the role assignments (see, a use case!). You can find the object id of the managed identity in the identity section of the Alert in the Portal. What role you assign it is up to you. I’m doing Reader because I’m lazy, but you could certainly craft a custom role if you’d like to (don’t forget to remove your permissions once you’ve completed this!).
az role assignment create --assignee-object-id "4f984694-b43c-4528-87e9-68aeab7478a3" --scope "/" --role "Reader"
You’re good to go! You now have an alert that will fire anytime there is any role assignment for User Access Administrator on the root “/” management group. Again, there should never be a role assignment for that role unless you’re temporarily using it for one of the use cases above.
The key things I want you to take away from this this post is the critical role Entra ID plays across all of the Microsoft Clouds. It’s important to understand how privilege in one product (Entra ID) can lead to privilege in another (Azure). Now you have a quick and easy security win you can crank out before Thanksgiving. Enjoy!
Hello again fellow geeks. Today I’m back with another Azure OpenAI Service (AOAI) post. I’ve talked in the past about the gaps in the native logging for the AOAI service and how the logs lack traceability and details on token usage to be used for chargebacks. I was lucky enough to work with Jake Wang and others on a reference architecture that could address these gaps using Azure API Manager (APIM). I also wrote some custom APIM policies to provide examples for how this information could be captured within APIM. I’ve observed customers coming up with creative solutions such as capturing the data within the application sitting in front of AOAI as a tactical means to get this data while more strategically using third-party API Gateway products such as Apigee, or even building custom highly functional and complex gateways. However, there was a use case that some of these solutions (such as the custom policies I wrote) didn’t account for, and that was streaming completions.
Like OpenAI’s API, the AOAI service API offers support for streaming chat completions. Streaming completions return the model’s completion as a series as events as the tokens are processed versus a non-streaming completion which returns the entire completion once the model is finished processing. The benefit of a streaming completion is a better user experience. There have been studies that show that any delay longer than 10 seconds won’t hold user attention. By streaming the completion as it’s generated the user is receiving that feedback that the website is responding.
Streaming Chat Completion
The OpenAI documentation points out a few challenges when using streaming completions. One of those challenges is the response from the API no longer includes token usage, which means you need to calculate token usage by some other means such as using OpenAI’s open source tokeniser tiktoken. It also makes it difficult to moderate content because only partial completions are received in each event. Outside of those challenges, there is also a challenge when using APIM. As my peer Shaun Callighan points out, Microsoft does not recommend logging the request/response body when dealing with a stream of server-events such as the API is returning with streaming chat completions because it can cause unexpected buffering (which it does with streaming chat completions). This means the application user will not get the behavior the application owner intended them to get. In my testing, nothing was returned until model finished the completion.
If using the Python SDK, you can make a chat completion streaming by adding the stream=true property to the ChatCompletion object as seen below.
response = openai.ChatCompletion.create(
engine=DEPLOYMENT_NAME,
messages=[
{
"role": "user",
"content": "Write me a bedtime story"
}
],
max_tokens=300,
stream=True
)
The body of the response includes a series of server-events such as the below.
You can move logging into the application and use APIM only for load balancing, authorization, and throttling.
You can insert a proxy logging solution behind APIM to handle logging of both streaming and non-streaming completions and use APIM only for load balancing, authorization, and throttling.
You can block streaming completions at APIM.
Option 1
Option 1 is workable at a small scale and is a good tactical solution if you need to get something out to production quickly. The challenge with this option is enforcing it at scale. If you have amazing governance within your organization and excellent SDLC maybe you can enforce this. In my experience, few organizations have the level of maturity needed for this. The other problem with this is ideally logging for the purposes of compliance should be implemented and enforced by another entity to ensure separation of duties.
Benefits
Quick and easy to put in place.
Considerations
Difficult to enforce at scale.
Puts the developers in charge of enforcing logging on themselves. Could be an issue with separation of duties.
Option 2
Option 2 is an interesting solution that my peer Shaun Callighan came up. In Shaun’s architecture a proxy-type solution is placed between APIM and AOAI and that solution handles parsing the requests and responses, calculating token usage, and logging the information to an Event Hub. They have even been kind enough to provide a sample solution demonstrating how this could be done with an Azure Function.
Allows you to use continue using APIM for the benefits around load balancing, authorization, and throttling.
Supports streaming chat completions.
Provides the logging necessary for compliance and chargebacks for both streaming and non-streaming chat completions.
Centralized enforcement of logging.
Considerations
You will need to develop your own code to parse the responses/responses, calculate chargebacks, and deliver the logs to Event Hub. (You could use Shaun’s code as a starting point)
You’ll need to ensure this proxy does not become a bottleneck. It will need to scale as requests to the AOAI instance scale along with APIM and whatever else you have in path of the user’s request.
Option 3
Option 3 is another valid option (and honestly a simple fix IMO) and may be where some customers end up in the near term. With this option you block the use of streaming completions at APIM with a custom policy snippet like below. If the developers are worried about the user experience, there is always the option to flash a “processing”-like message in the text window while the model processes the completion.
Benefits
Allows you to continue using APIM for logging, load balancing, throttling, and authorization.
No new code introduced.
Centralized enforcement of logging.
No additional bottlenecks.
Considerations
Your developers may hate you for this.
There may be a legitimate use case where stream chat completions are required.
Since Shaun has a proof-of-concept example for option 2, I figured I’d showcase a sample APIM policy snippet for option 3. In the APIM policy snippet below, I determine if the stream property is included in the request body and store the value in a variable (it will be true or false). I then check the variable to see if the value is true, and if so I return a 404 status code with the message that streaming chat completions are not allowed.
<!-- Capture the value of the streaming property if it is included -->
<choose>
<when condition="@(context.Request.Body.As<JObject>(true)["stream"] != null && context.Request.Body.As<JObject>(true)["stream"].Type != JTokenType.Null)">
<set-variable name="isStream" value="@{
var content = (context.Request.Body?.As<JObject>(true));
string streamValue = content["stream"].ToString();
return streamValue;
}" />
</when>
</choose>
<!-- Blocks streaming completions and returns 404 -->
<choose>
<when condition="@(context.Variables.GetValueOrDefault<string>("isStream","false").Equals("true", StringComparison.OrdinalIgnoreCase))">
<return-response>
<set-status code="404" reason="BlockStreaming" />
<set-header name="Microsoft-Azure-Api-Management-Correlation-Id" exists-action="override">
<value>@{return Guid.NewGuid().ToString();}</value>
</set-header>
<set-body>Streaming chat completions are not allowed by this organization.</set-body>
</return-response>
</when>
</choose>
If you ignore streaming chat completions and try to use a policy such as this one, the model will complete the completion but APIM will throw a 500 status code back at the developer because the structure of a streaming response doesn’t look like the structure of a non-streaming response and it can’t be parsed using that policy’s logic. This means you’ll be throwing money out of the window and potentially struggling with troubleshooting root cause. TLDR, pick an option above to deal with streaming and get it in place if you’re using APIM for logging today or plan to.
Last but not least, I want to link to a wonderful policy snippet by Shaun Callighan. This policy snippet dumps the trace logs from APIM into the headers returned in the response from APIM. This is incredibly helpful when troubleshooting a 500 status code returned by APIM.
Well folks, that wraps up this short blog post on this Friday afternoon. Have a great weekend and happy holidays!
5/28/2024 – Updated to mention that objectid of security principal is now included in native diagnostic logs
Hello again folks! Today I’m going to bounce back into AOAI (Azure OpenAI Service) mode and cover a topic that frequently comes up with my customers in regards to securing the service. Over the past year I’ve covered the infrastructure and security controls available within the AOAI. Much of that focus was on accessing the service through an SDK (software development kit) or directly through the API. Today I’m going to spend some time talking about the security controls available to secure the Azure OpenAI Studio, which I’m going to refer to as Studio for the rest of this post.
If you’re unfamiliar with Studio, it’s a GUI-based experience for interacting with the data plane of the AOAI service. In my authorization post, I cover the difference between the service’s management and data planes. At a high level, the management plane is for operations “on the service” while the data plane is for operations “in the service”.
Azure OpenAI Service Management Plane vs Data Plane
Microsoft recommends using an SDK or the API directly when interacting with the data plane of the service. It’s a good recommendation because there are lots of knobs for you to turn to lock down the service and address gaps in the service. When the service is using through the Azure OpenAI Studio, you lose the ability to inject some type of control component between the user’s endpoint and the instance of AOAI. The rest of this post will cover why that is, what controls are available to you, and what risks you’ll have to accept if you opt to make Studio available to your users.
Before I jump into the details of what you get and what you don’t get, I want to cover what some of the main use cases are for using Studio versus accessing the service through an SDK or direct through the API. First and foremost, it should be obvious that GUIs are much more accessible than having to write code to interact with the API. For example, say I’m performing a PoC (proof-of-concept) of the service and I want to quickly test the gpt 3.5 model’s ability to answer a question in my field. For that I can use the Completions interface within Studio to get a chat-like interface with zero coding.
Example of Chat Completion functionality in Azure OpenAI Studio
Another use case may be I want a simple way to test the models on my organization’s data to see if the models can provide value to that data. I don’t want to invest a ton of time coding to perform this functionality because I don’t yet know if the models will be able to provide any value on top of my data.
A lot of the use for Studio comes down to its simplicity of use. If you need to do some basic PoC with minimal funding, using Studio can be a nice shortcut to doing all the code you’d need to do in order to interact with the API to perform the actions.
Long story short, if you’re offering this service to your business units you’re likely going to be asked to provide Studio access to your users. My goal here is to help you understand the risks and mitigations of doing so.
So how does the Azure OpenAI Studio work? It appears to use an MVC (model-view-controller) architecture (or something similar to it for those application developer purists who are much smarter than me). In simple terms for non-developers like myself, the Studio application instructs the user’s browser which data plane endpoints to call and then provides a pretty view in the user’s browser of the responses received from those endpoints.
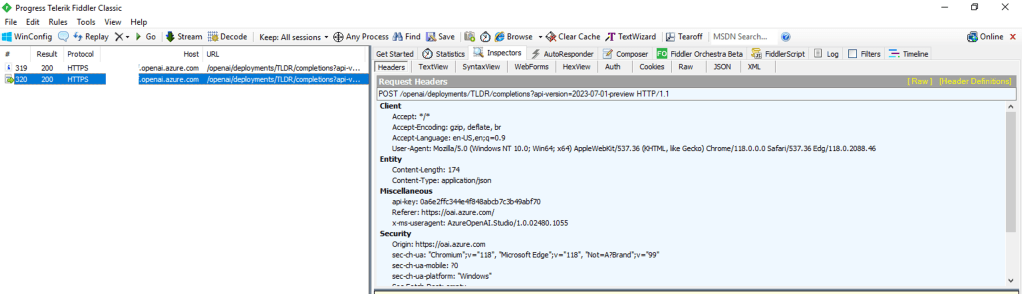
For you non-developers like myself, I find it helpful to perform an action within Studio and then review the Fiddler capture to observe what the browser did. In the Fiddler capture below, I used the Chat Completion interface in Studio to send a request a completion. You can see that the request was sent from my browser to the data plane endpoint of the service (openai.azure.com).
Fiddler capture of Chat Completion in Azure OpenAI Studio
This trait of the Studio can work to your advantage when you need to secure the Studio. If the calls are made from the user’s endpoint to the data plane, then that means network controls around the data plane can be used to enforce control over access to the Studio for the instance of AOAI. As I covered in my prior posts, AOAI is no different from other Microsoft PaaS services and provides the standard network controls which include the service firewall and support for Private Endpoints.
A common security standard for organizations using Azure is to use Private Endpoints for PaaS services. Private Endpoints allow you to restrict access to the public IP of a PaaS service and limit it to access through an endpoint deployed in the customer’s virtual network. Accessing the service through the Private Endpoint requires the user’s endpoint to be within your organization’s private network. This means by creating a Private Endpoint you can block access to access to the AOAI instance through Studio to endpoints within your private network. If the user attempts to access the AOAI instance through Studio outside of the private network, they’ll be blocked and will receive the error you see below.
Network controls blocking access through Azure OpenAI Studio
Placing your AOAI instance behind a Private Endpoint will be your primary means of controlling access to an AOAI instance through Studio. Creating the private endpoint and blocking public access keeps user’s from accessing the AOAI instance through Studio when hitting the public IP. However, users can still reach the AOAI instance through Studio if they are on the private network. You can lock that down by wrapping an NSG (Network Security Group) around the subnet containing the Private Endpoint, turning on Private Endpoint Network Policies in the subnet, and placing some type of mediator (such an Azure API Management instance) between the user’s endpoint and the AOAI instance. That will restrict the users to the API when interacting with the AOAI instance.
Example AOAI architecture
Outside of network controls, you don’t have much ability to control Studio access. There are no specific RBAC permissions that I’m aware of today that could be stripped from an RBAC role to prevent access to Studio. When it comes to authorization you should strive for least privilege as you’ve always done. My authorization blog has some guidance on how to handle that within the service.
Now that you understand what controls you have, let’s talk about the risks you’re going to need to accept if you plan on granting users access to Studio.
First and foremost, you’re going to need to accept the very basic logging provided by the diagnostics logging available within an AOAI instance. As I cover in the linked post above, the logging is minimal. Prompts and responses will not be logged, traceability in the logs will be limited, and you won’t get metrics as to token usage per call. The lack of visibility into prompts and responses becomes all that much more critical if shut off the built in content filtering and abuse monitoring.
Next up, you won’t have the ability to limit the usage of service on a per user or per app basis. AOAI has API limits around requests and tokens. There are capabilities today to control this on per user or per app basis within a single instance of AOAI today.
Let me summarize what we covered today:
Network controls are your primary means to securing access to an AOAI instance through the Azure OpenAI Studio
Placing an AOAI instance behind a Private Endpoint and blocking public access restrict Azure OpenAI Studio access to the AOAI instance to endpoints within your private network
Azure OpenAI Studio access to an AOAI instance can be blocked completely by placing the AOAI instance behind a private endpoint, inserting some sort of mediation solution (such as API Management, and wrapping an NSG around the subnet containing the Private Endpoint which blocks all access but traffic from the mediator.
Exercise least privilege using Azure RBAC but be aware there is no specific permission that allows access to the Azure OpenAI Studio
The diagnostic logs provided limited information. Prompts and responses are not logged to the diagnostic logs and neither are token consumption. The former will mean you don’t have visibility into the prompts users are making (think abuse, inclusion of PII, etc) and the latter means you won’t be able to tell who is creating the costs within the instance.
Considering all of the above, my recommendation to customers it to establish an approval process for usage of Studio and ensure there is a strong business need to justify accepting the risks outlined above. The lack of logging is the real gut punch for me. That is a lot of risk, especially since most regulated orgs opt out of content filtering and abuse monitoring.
Nothing to fancy in this post, but hopefully it helps some folks better understand the security options for Azure OpenAI Studio access.