Update 11/4/2024 – Added limitations
Update 10/11/2024 – Updated with generally available announcement
Welcome back! Today I’m going to step back from the Generative AI world and talk about some good ole networking. Networking is one of those technical components of every solution that gets glossed over until the rubber hits the road and the application graduates to “production-worthy”. Sitting happily beside security, it’s the topic I’m most often asked to help out with at Microsoft. I’m going to share a new feature has gone generally available under the radar that is pretty damn cool, even if a bit confusing.
Organizations in the regulated space frequently have security controls where a simple 5-tuple-based firewall rule at OSI layer 4 won’t suffice and traffic inspection needs to occur to analyze layer 7. Take for an example a publicly facing web application deployed to Azure. These applications can be subject to traffic inspection at multiple layers like an edge security service (Akamai, CloudFlare, FrontDoor, etc) and again when the traffic enters the customer’s virtual through a security appliance (F5, Palo Alto, Application Gateway, Azure Firewall, etc). Most of the time you can get away with those two inspection points (edge security service and security appliance deployed into virtual network) for public traffic and one inspection point for private traffic (security appliance deployed into virtual network and umpteenth number of security appliances on-premises). However, that isn’t always the case.
Many customers I work with have robust inspection requirements that may require multiple inspection points within Azure. The two most common patterns where this pops up is when traffic first moves through an Application Gateway or APIM (API Management) instance. In these scenarios some customers want to funnel the traffic through an additional inspection point such as their third-party firewall for additional checks or a centralized choke point managed by information security (in the event Application Gateways / APIM have been democratized). When the backend is a traditional virtual machine or virtual network injected/integrated (think something like an App Service Environment v3) the routing is quite simple and looks like something like the below.

In the above image we slap a custom route table on the Application Gateway subnet, and add a user-defined route that says when contacting the subnet containing the frontend resources of the application, it needs to go the firewall first. To ensure the symmetry of return traffic, we put a route table on the frontend subnet with a user-defined route that says communication to the Application Gateway subnet needs to also go to the firewall. The routes in these two route tables are more specific than the system route for the virtual network and take precedence forcing both the incoming and return traffic to flow symmetrically through the firewall. Easy enough.
The routing when inspecting traffic to services which receive their inbound traffic via a Private Endpoint (such as an App Service running in a Premium App Services Plan, a Storage Account, a Key Vault, etc) that inspection gets more challenging. These challenges exist for both controlling the traffic to the Private Endpoint and controlling the return traffic.
When a Private Endpoint is provisioned in a virtual network, a new system route is injected into the route tables of each subnet in that virtual network AND any peered virtual networks. This route is a /32 for the IP address assigned to the network interface associated with the Private Endpoint as seen in the image below.

Historically, to work around this you had to drop /32 routes everywhere to override those routes to push the incoming traffic to the Private Endpoints through an inspection point. This was a nightmare at scale as you can imagine. Back in August 2023, Microsoft introduced what they call Private Endpoint Network Policies, which is a property of a subnet that allows you to better manage this routing (in addition to optionally enforcing Network Security Groups on Private Endpoints) by allowing less specific routes to override the more specific Private Endpoint /32 routes. You set this property to Enabled (both this routing feature and network security group enforcement) or RouteTableEnabled (just this routing feature). This property is set on the subnet you place the Private Endpoints into. Yeah I know, confusing because that is not how routing is supposed to work (where less specific routes of the same length override more specific routes), but this is an SDN (software defined network) so they’ll do what they please and you’ll like it.

While this feature helped to address traffic to the Private Endpoint, handling the return traffic wasn’t so simple. Wrapping a custom route table around a subnet containing Private Endpoints does nothing to control return traffic from the Private Endpoints. They do not care about your user-defined routes and won’t honor them. This created an asymmetric traffic flow where incoming traffic was routed through the inspection point but return traffic bypassed it and went direct to the calling endpoint.
This misconfiguration was very common in customer environments and rarely was noticed because many TCP sessions with Private Endpoints are short lived and thus the calling client isn’t affected by the TCP RST sent by the firewall after X number of minutes. Customers could work around this by SNATing to the NVA’s (inspection point) IP address and ensure the return traffic was sent back to the NVA before it was passed back to the calling client. What made it more confusing was some services “just worked” because Microsoft was handling that symmetry in the data plane of the SDN. Azure Storage was an example of such a service. If you’re interested in understanding the old behavior, check out this post.
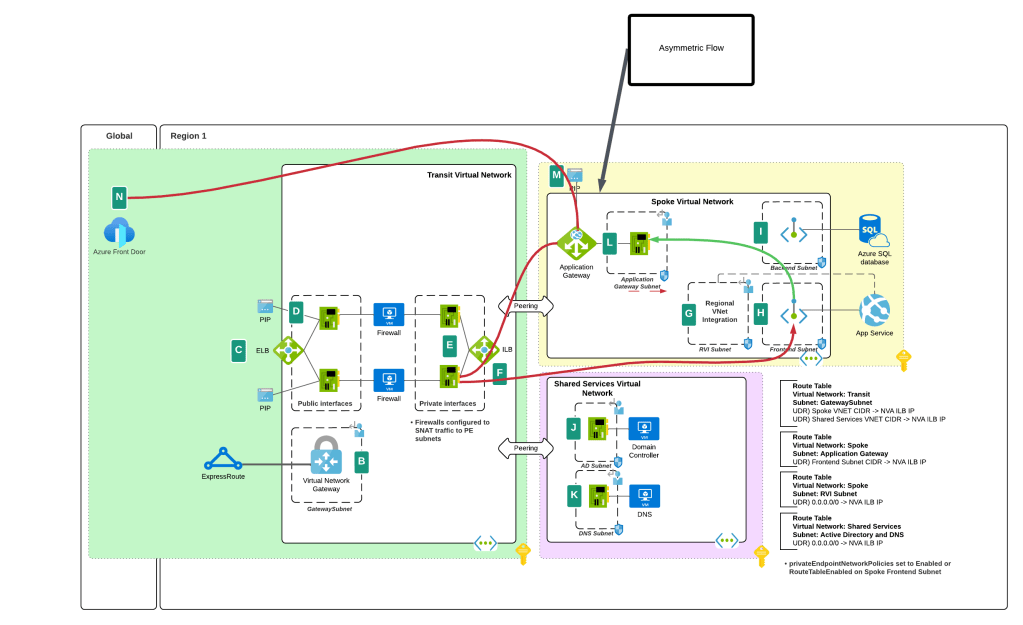
You’ll notice I said “prior” behavior. Yes folks, SNATing when using a 3rd-party NVA (announcement is specific to 3rd-party NVAs. Those of you using Azure Firewall in a virtual network, Azure Firewall in a VWAN Secure Hub, or a 3rd-party NVA in a VWAN Secure Hub will need to continue to SNAT for now (As of 11/2024) until this feature is extended to those use case.
I bet you’re thinking “Oh cool, Microsoft is now having Private Endpoints honor user-defined routes in route tables”. Ha ha, that would make far too much sense! Instead Microsoft has chosen to require resource tags on the NICs of the NVAs to remove the SNAT requirement. Yeah, wouldn’t have been my choice either but here we are. Additionally, in my testing, I had it working without the resource tags to get a symmetric flow of traffic. My assumption (and total assumption as an unimportant person at Microsoft) is that this may be the default behavior on some of the newer SDN stacks while older SDN stacks may require the tags. Either way, do what the documentation says and put the tags in place.
As of today (10/11/2024) the generally available documentation is confusing as to what you need to do. I’ve provided some feedback to the author to fix some of the wording, but in the meantime let me explain what you need to do. You need to create a resource tag on either the NIC (non-VMSS) or VM instance (VMSS) that has a key of disableSnatOnPL with a value of true.
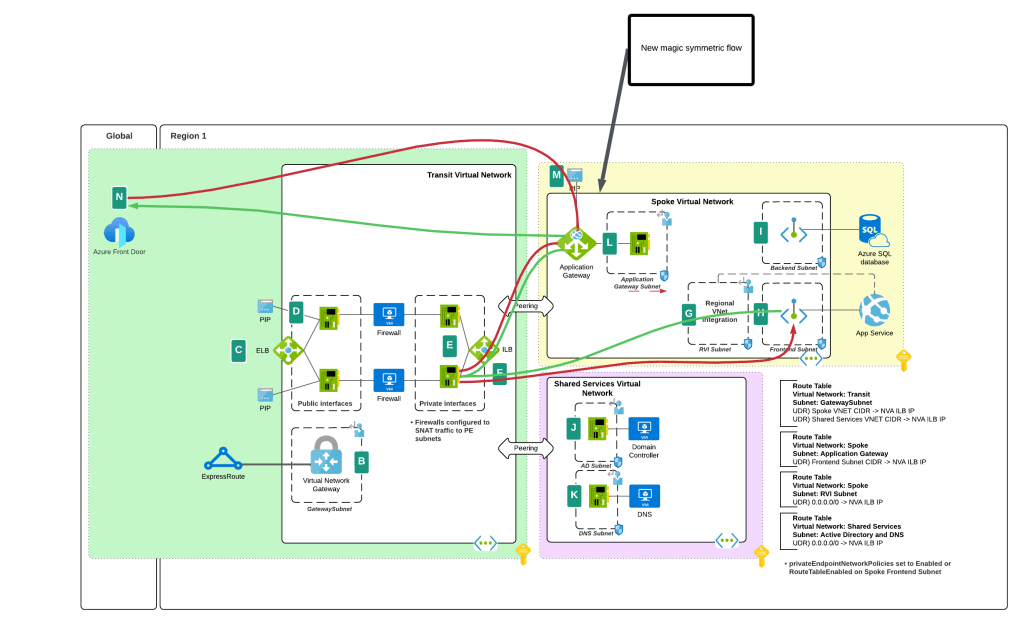
TLDR; SNAT should no longer be required to ensure symmetric traffic flow when placing an NVA between an endpoint and a Private Endpoint if you have the proper resource tag in place. My testing of the new feature was done in Central US and Canada Central with both Azure Key Vault and Azure SQL. I tested when the calling endpoint was within the same virtual network, when it was in a peered virtual network connected in a hub and spoke environment, and when the calling machine was on-premises calling a private endpoint in a spoke. In all scenarios the NVA showed a symmetric flow of traffic in a packet capture.







