
This is part of my series on Microsoft Foundry:
- Microsoft Foundry’s Evolution
- Microsoft Foundry BYO AI Gateway (BYO Model) – Part 1
- Microsoft Foundry BYO AI Gateway (BYO Model) – Part 2
- Microsoft Foundry BYO AI Gateway (BYO Model) – Part 3
- Microsoft Foundry Publishing Foundry Agents to Microsoft Teams – Part 1
- Microsoft Foundry Publishing Foundry Agents to Microsoft Teams – Part 2
Welcome back folks! Today we’re gonna delve deep into the weeds to look at the current process for publishing Foundry agents to Microsoft Teams. I say current, because Microsoft Foundry and everything surrounding it lives in a dynamic world. Changes come fast and frequently. What I present today, may not be true in two weeks. I attempt to keep my posts up to date, but always remember to check the date of the post and review public documentation for the “official” word. With that disclaimer in play, let’s jump in.
The Background
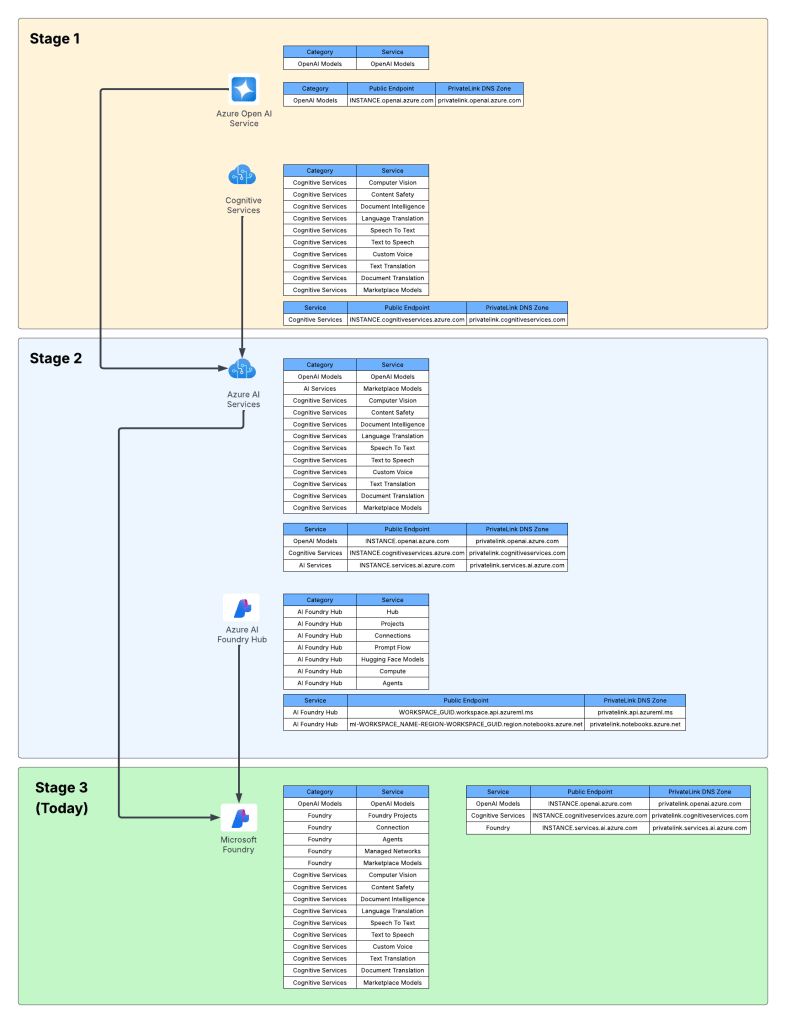
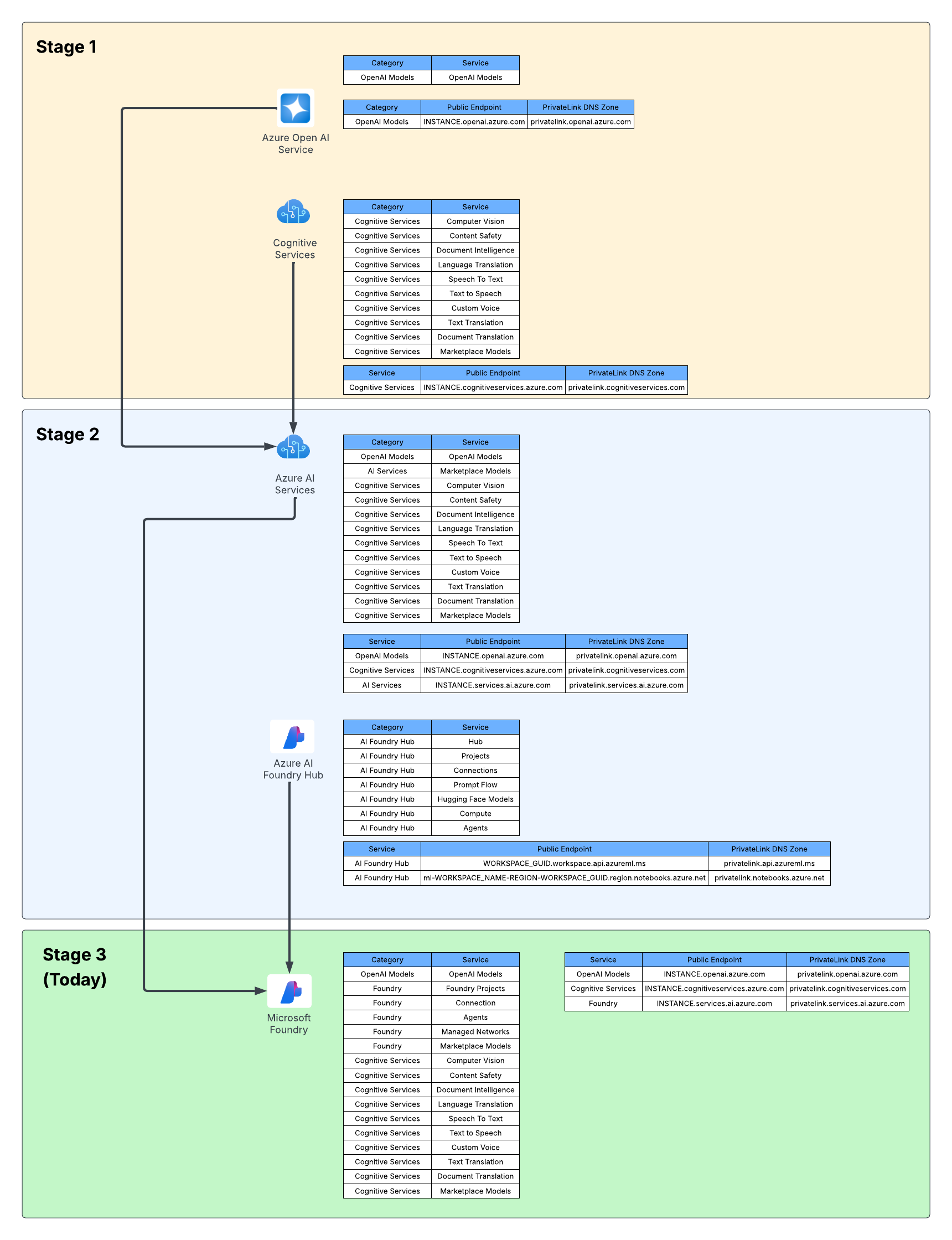
Microsoft Foundry is a collection of a crapload of different services. I hesitate to call it a “product” because with how big the feature scope is it’s almost a platform rather than a product at this point. You have models-as-service, Foundry tools (FKA as AI Services FKA as Cognitive Services), Foundry Toolbox (LOVE this feature and will be writing something up about it soon), Content Understanding, Foundry IQ (not really Foundry IMO, more so AI Search but marketing loves the term Foundry), and Foundry Agent Service. I’m sure come Microsoft Build and Microsoft Ignite there will be even more in that umbrella. It’s an interesting journey on how this service came to be. You can take a read through my prior post which walks through the evolution of the service. For this post I’m going to focus specifically on Foundry Agents.
The Foundry Agent feature is probably one of the most dynamic features (or sub-service) of Microsoft Foundry because the technology area it supports changes daily which drives needs for the product to adapt and grow. Some of the benefits that pop into my mind of Foundry Agents vs running an agent on your own compute (in an on-premises Kubernetes cluster, in EKS, AKS, ACA, what have you) is:
- Shift the management and scaling of the compute to Microsoft
- Versioning out-of-the-box
- Crank an agent out since 90% of the work is already done for you (Foundry Hosted Agents are another story)
- Get access to all the Foundry Agent Tools out of the box (this benefit will likely be phased out with the introduction of Foundry Toolbox IMO)
- Ability to directly publish the agent to Microsoft Teams without having to figure out that integration yourself
The final bullet point will be the focus of the rest of the post. Recently, I found time to play with that feature and decided to dive into it after a great blog post by my peer Graeme Foster. I highly recommend you take a read through Graeme’s post and treat his post as the “official” recommendation vs whatever I blather about here. The part that interested me about his write-up was the call out to Azure AI Bot Services. Bot Services is an Azure service I’ve touched a few times, but never really dove deeply into. Last year my buddy Mike Piskorski and I helped a customer onboard a Teams recording bot into a regulated organization’s network. We dove deeply into the networking side of things to get the traffic flowing, but never really dissected the inner workings of it (limited bandwidth, story of my life). Since exposing an agent direct to a user in Microsoft Teams so users can intact with it is a super common ask, and Foundry Agents provide for this out of the box, I thought it would be as good time as any to dig in.
The Portal Experience
The official documentation around the Portal process is documented here, but I wanted to dig into some the guts of it. Like Microsoft has done much of its existence, it likes to make things a “push of the blue button”. This integration is no different. After logging into the Foundry Portal and creating an agent I get a pretty Publish button in the top right hand corner as seen below.
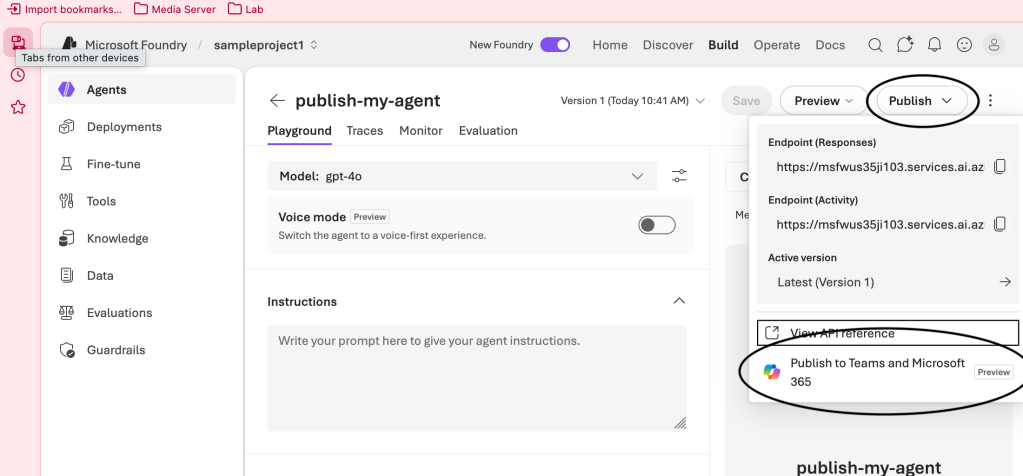
I assume in my head, sweet, let’s do this! I hover over the button to click it, but oh no, the pop up below surfaces. For this button to be available to you, the user needs to have the Contributor or Owner at the resource group or subscription level. We’ll see why in a few minutes.
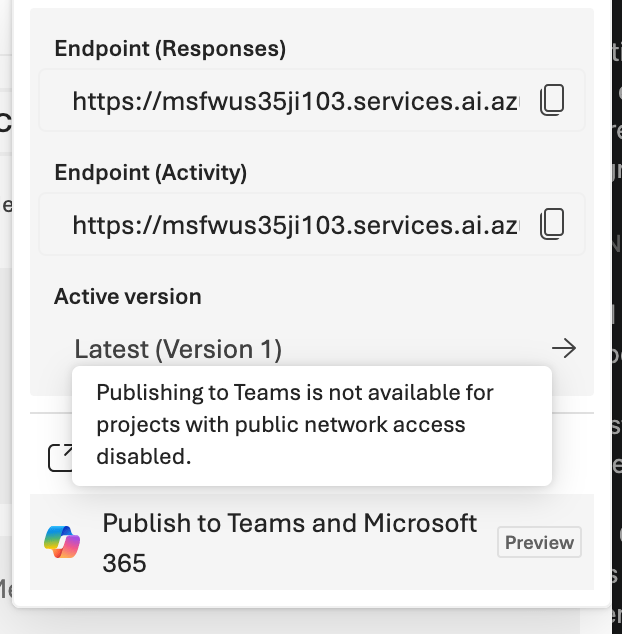
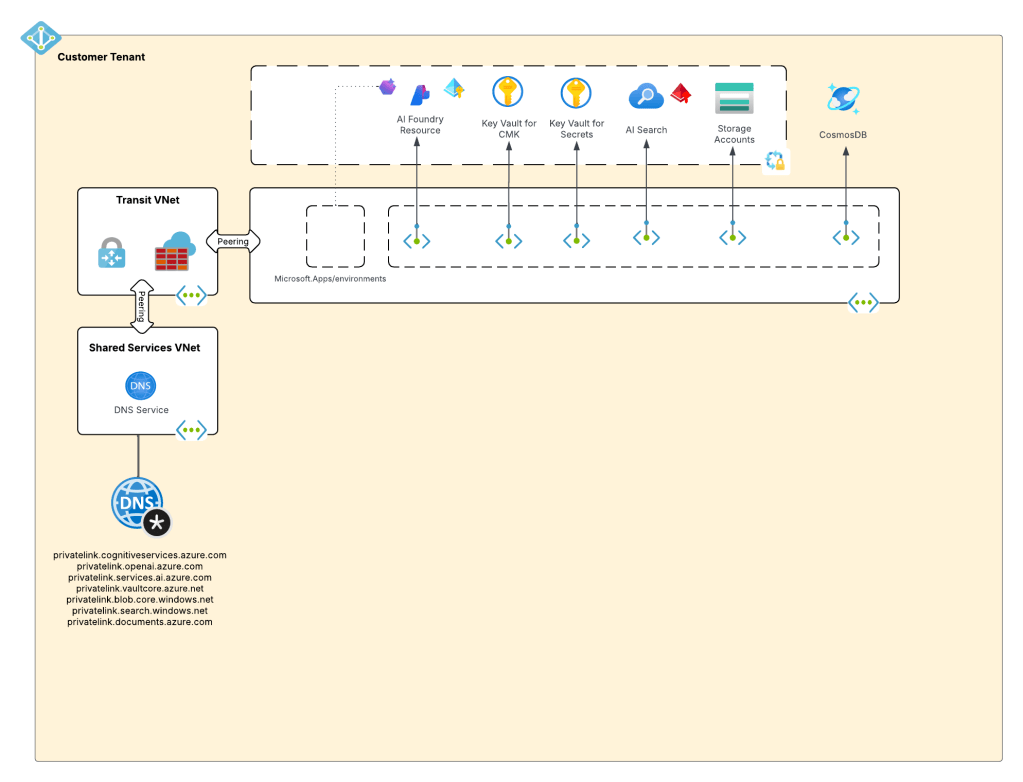
The pop up message tells me I can’t publish my Foundry resource if public network access is disabled (NOTE: this will be changing at some point). So what does this message mean? Without derailing this entire post with a deep dive into Foundry Agent networking, I’ll keep the explanation brief. For my Foundry deployment, I’ve chosen to block public inbound traffic to the Foundry resource and am forcing everything through a Private Endpoint. This control blocks whatever orchestration this button does today. One option is to enable public networking, push the button, and then disable public network access (not great). There is another programmatic option for customers that have public network access off and walk through in detail in my next post, but for now let’s enable public network access and step through the flow in the Portal.
Once public network access is re-enabled, I’m able to click the magical button. Pushing the button brings up the first window Publish to Teams and Microsoft 365. Here a few things happen. First, we’re given the option to customize what will ultimately be used to provide information about the agent to the Teams App Catalog or manifest file. I’m no Teams guy and won’t fake being one so my dumb guy explanation of the Teams App Catalog is its the central repository for Teams Apps (and agents) available for consumption by an organization’s Teams users. The manifest file is basically the same information put in json form that can be used to sideload the app (or agent in this use case) which is a way you can load the app into Teams for yourself and is typically used in testing scenarios before pushing up to the Teams App Catalog.
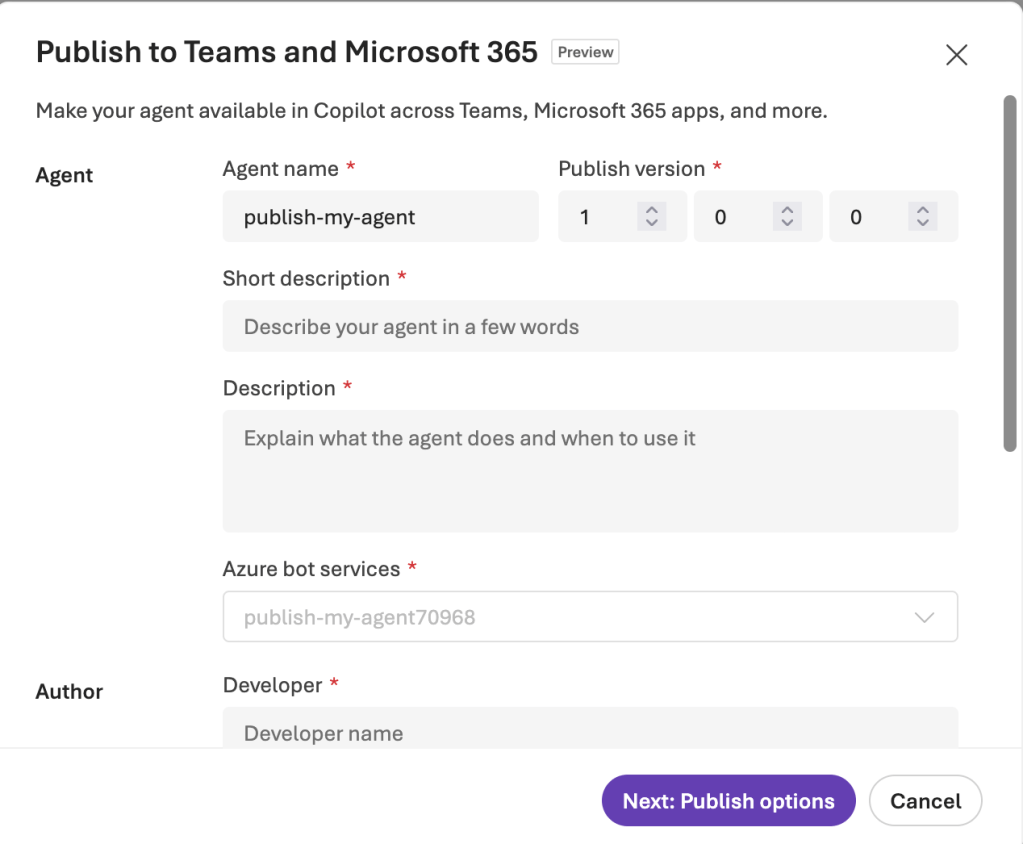
The other thing this step does is auto-provision an Bot Service resource in Azure. This is where the requirement for Contributor or Owner comes in (and is another reason why this GUI-drive process won’t work for most enterprises). It places it in the same resource group as the Foundry resource. This is probably not something you want happening automatically and this behavior is likely to change in the future allowing you to select a pre-created Bot Service resource. Think of the Bot Service resource as a metadata resource of sorts (again, my explanation and probably only 50% right, but I got a head nod on the explanation from my excellent and much smarter peer Shaun Callighan so there is that). It will help the Azure AI Bot Service facilitate the communication between Microsoft Teams and the Foundry Agent. I’ll dig into more details on later in this post.
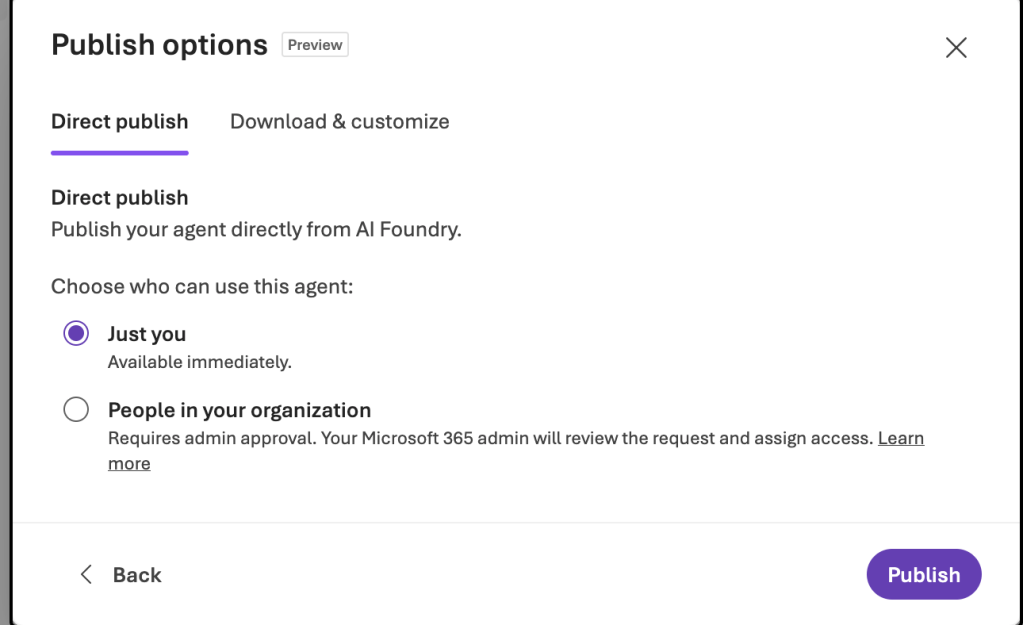
I then hit the Next: Publish Options button and I’m faced with the Publish options window. Here I can choose to publish the agent to Teams just for my user or to publish it to the Teams App Catalog for all users (which will require a Teams administrator to approve). Optionally, I can download the Teams manifest file and further customize it (add a custom icon or something more fancy that is outside my limited Teams knowledge).
Publishing it to the Teams App Catalog will require an administrator to approve it in the Microsoft 365 Admin portal. The request will immediately appear in the Microsoft 365 Admin Portal in the request section as seen below. From there you’ll be given some options as to how you want to distribute it users across Microsoft Teams. After approval and installation, in my experience it can take a fair amount of time (6+ hours – 1 day) for the agent to be available to Teams users to use.
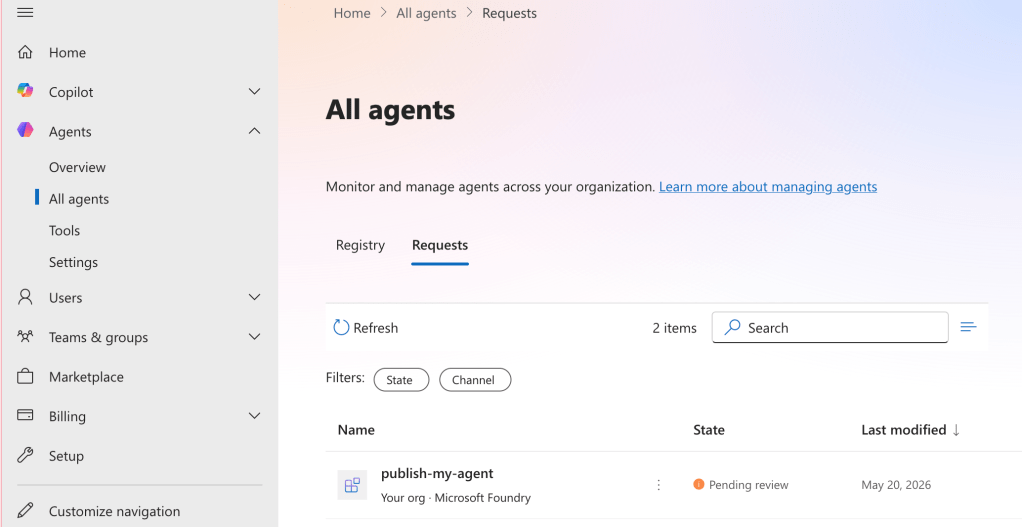
For the purposes of this walkthrough, I’m going to choose the Just you option and then I’ll hit the Publish button. Once complete, you’ll get a message indicating the publish was successful.
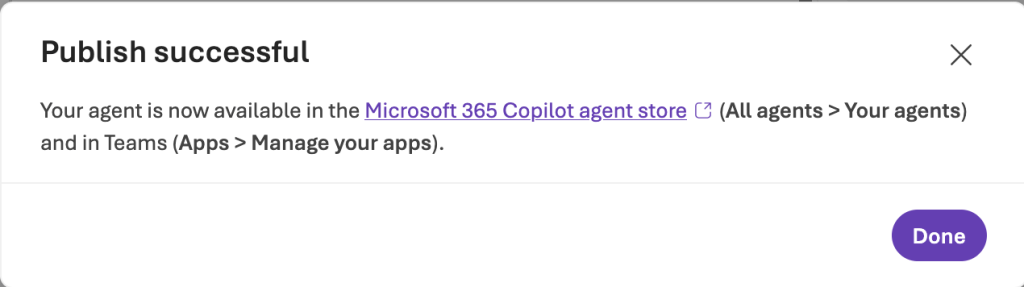
Bouncing over to the Microsoft Teams client, I see the new agent available to install.
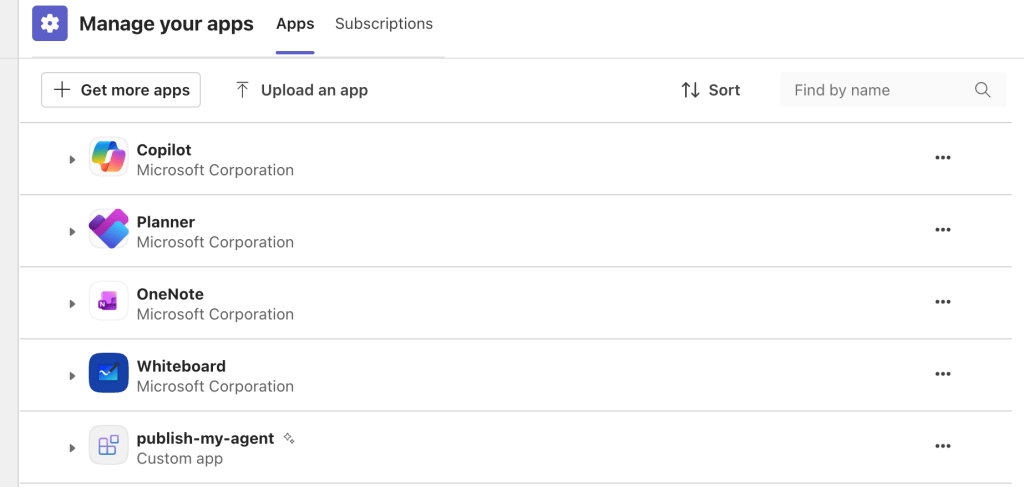
Once it’s added and I send my first message to the agent, I’m prompted to sign in to Microsoft Foundry. This is triggered because the agent on the other side needs to know who I am in order to authorize me to access the agent.
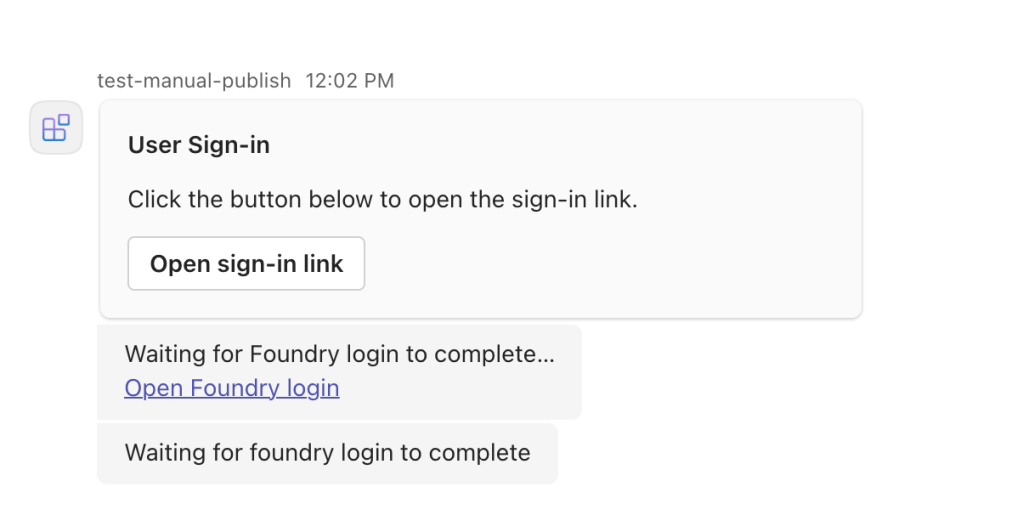
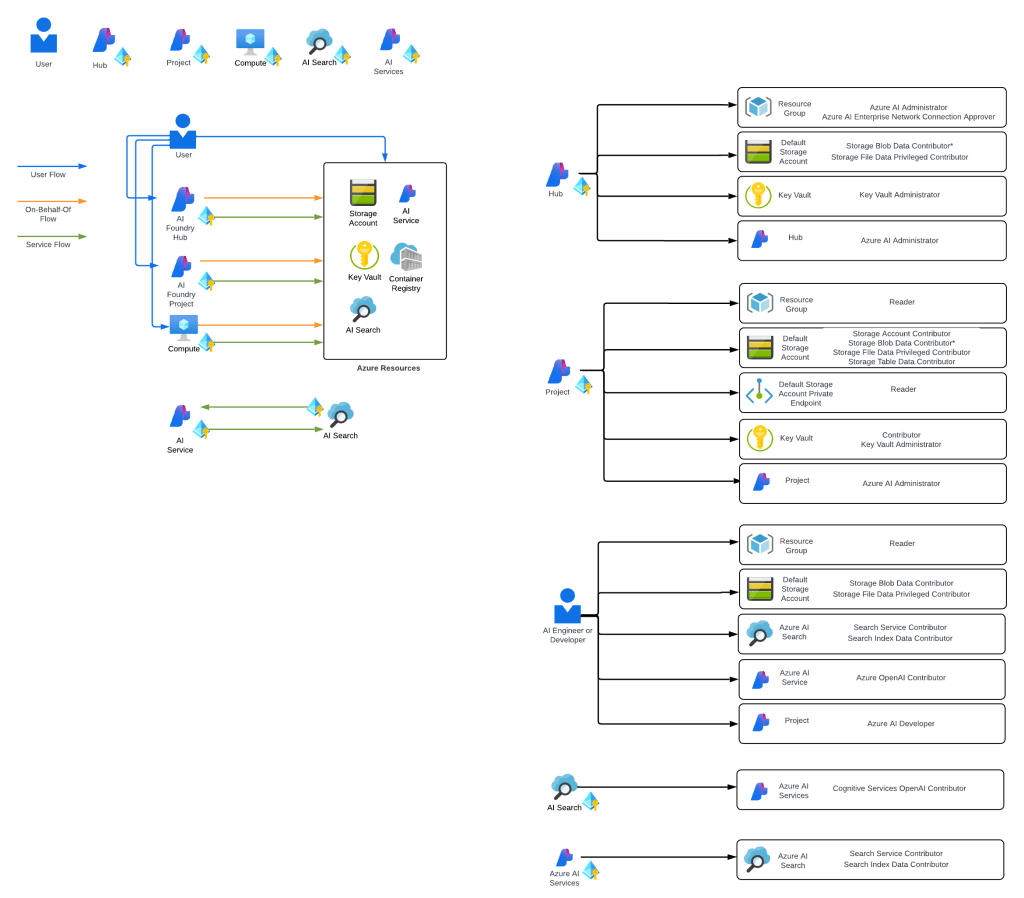
If my user isn’t authorized (doesn’t hold the Foundry User (FKA as Azure AI User)) Azure RBAC role over the Foundry resource I’m denied and I can’t interact with the agent.

Understanding this user experience and RBAC requirement is important. While the Publish button can be used to push the agent as a Teams App to your users, the users themselves still need to hold the appropriate Azure RBAC role (Foundry User in this scenario or similar level permissions) to interact with them. While this is a tad annoying, it’s actually a nice belt and suspenders security control to ensure only trusted users get access to the agent.
Excellent, so we pushed a button and a lot of stuff happened. Well, what stuff happened? What if, like any normal enterprise, I don’t want to give my business unit contributor or owner at the Azure subscription level? What if, again like any normal enterprise, I have different groups in charge of Foundry, Azure general, and Teams? What if I want to do this programmatically? These were the questions on the top of my mind. So now let’s dive into the weeds and reverse engineer this process.
What the hell is happening when I push this button?
This is naturally what went through my head. Before I annoyed the awesome people within the Foundry product group (and yes, these are some of the nicest and smartest people at Microsoft I’ve dealt with in my years here) I wanted to see if I could figure it out myself.
My first step was to turn on debug mode in the browser and look at the network capture. My hope was that I’d see calls made to the Microsoft Graph API (for Teams stuff), the ARM API for Azure stuff, and Foundry data-plane API for data plane stuff. Instead of that, I saw calls made to what to the following endpoints:
- Press Publish to Teams and Microsoft 365 button
- https://ai.azure.com/nextgen/api/query?listBotServicesResolver -> As best I can tell, this is querying to see if a Bot Service already exist.
- https://ai.azure.com/nextgen/api/createBotService -> This makes the call that triggers the creation of the Bot Service resource in Azure.
- Press Next: Publish Options
- https://ai.azure.com/nextgen/api/prepareAgentsForTeams -> Generates the manifest file that you can download?
- Press Publish
What this told me was the Product Group has built their own orchestration layer on top of whatever is being done to the Microsoft Graph, ARM, and Foundry data-plane APIs. This didn’t get me any closer to figuring out what was going on. I had theories, but no way to validate them. At that point I went to the product group and one of those wonderful human beings began to peel away those layers of the onion by providing a programmatic way to run through process. I read through her code, converted it from PowerShell/Bicep into Python and Terraform and documented this high-level process. I’ll share and walk through all of this in my next post.
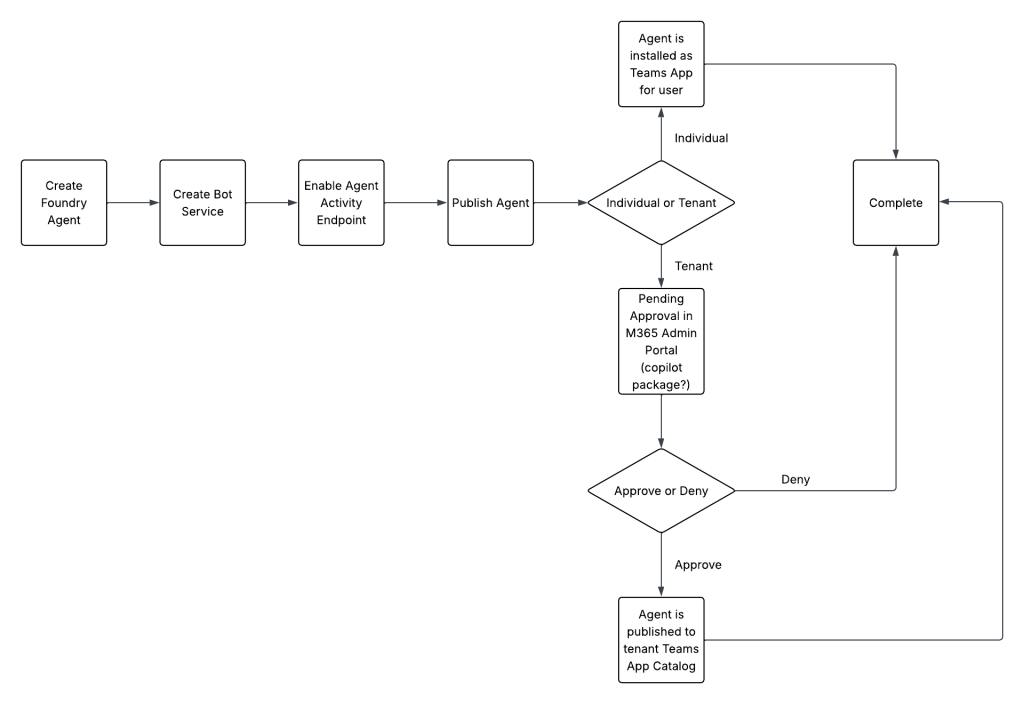
This is very high-level (we’ll look at the code-based implementation next post) but it’s the best I could piece together from the programmatic steps. It’s likely missing some steps because the one step I’m not super clear on is the step labeled Pending approval in M365 Admin Portal. The reason that piece is a bit unclear for me is two fold. One, even programmatically, this is done through a Foundry API hiding what’s done in other APIs from me. Two, I’m fairly certain it’s using new features the Microsoft Entra Agent Registry (now a part of Agent 365) and those APIs are largely locked behind Agent 365 licensing which I’m still waiting on approval for my tenant. My theory at this point is the Foundry API call is creating an agent instance within the Entra ID Agent Registry and/or something with CoPilot packages. I’ll add more detail to this if I get more insight into it once I get access to Agent 365.
Either way, once I had that high level workflow out of my brain and on digital paper, I was ready to take the product groups PowerShell / Bicep and rework it into a Jupyter Notebook which I’ll run through next post. Before I go there, I wanted to spend a bit of time on the Bot Service piece since that has always been a real mystery for me and many of my Azure peers.
What does the Bot Service do?
The Azure AI Bot Service (as it’s now called) has historically been used to build bots that can be exposed to Teams. I’m sure there are many other smarter uses, but that’s where I’ve seen it typically pop up in my time at Microsoft. As I mentioned earlier, my buddy Mike and I worked on helping a customer integrate a Teams Recording Bot that used the Bot Service. Today, the hot usage is exposing agents built within CoPilot Studio or Foundry to Teams as chat bots.
From an infra guy’s view, the Bot Service has always been this thing I knew existed, kinda understood how it worked from a network perspective and what it delivered form a value perspective, but really only focused on getting the traffic from Teams to the Bot Service into the application running the Bot Service Framework. Typically, this required exposing an application deployed to the customer’s private network to the Microsoft public backbone so it the Bot Service Connector (they relay piece of the service, my take) can hit the Bot app. This process would typically require placing the application behind a firewall with DNAT, behind an App Gateway (for l7 load balancing, WAF, and header checks) or some other layer 7 load balancer), behind FrontDoor in combination with PrivateLink, or behind something more complex such as a layer 7 load balancer in combination with an API Gateway (such as API Management) to do additional validation of the JWT as mentioned in Graeme’s blog I linked at the beginning of this post. Great, we got packets flowing, but much of the service was still a black box. I wanted to know more.
In my searching of the web, I came across an absolutely amazing blog post by Moim Hossain. Moim goes into an insane amount of detail as to how the Bot Service words under the hood. I’m not going to repeat everything he says, because I really anyone using Azure that will touch the Bot Service should read Moim’s rundown. It is THAT good.
Based on Moim’s blog (yeah I’m going to force you to read it if you want the details), I put together the high level flow of how I believe the Bot Service works. Likely missing pieces, but I feel like it’s more than what’s out there today.
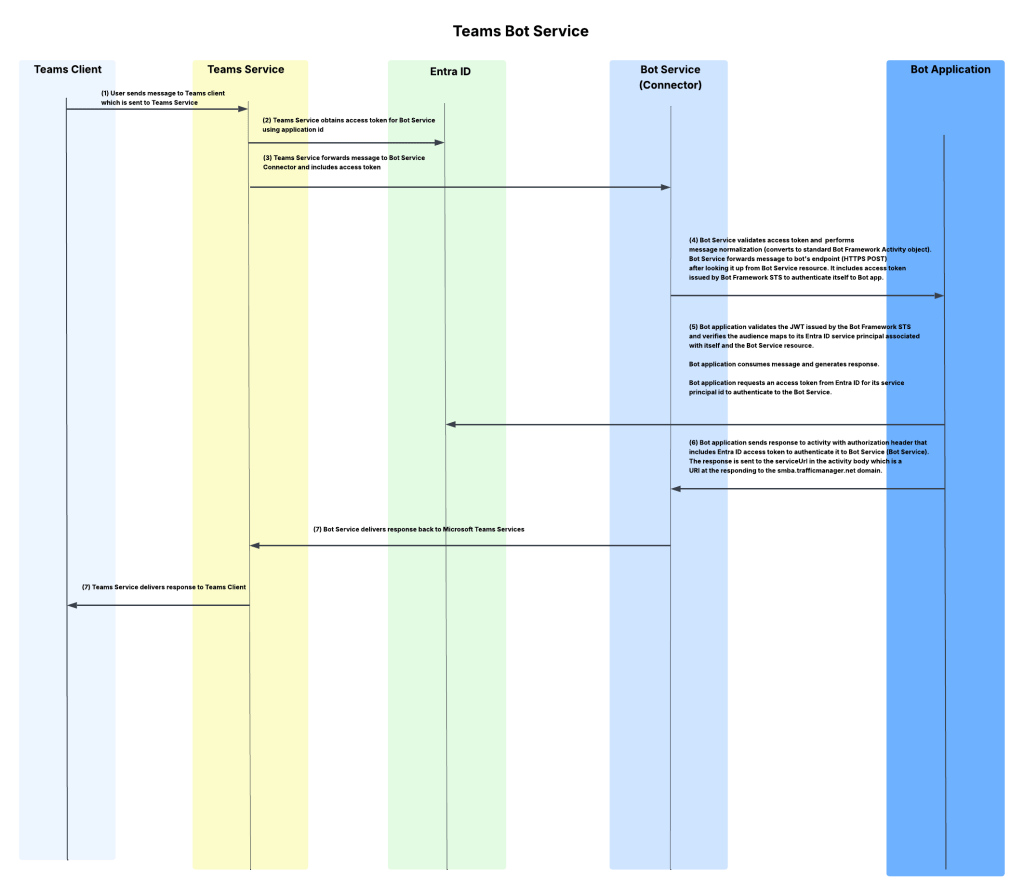
After reading Moim’s blog and referencing the flow above we can see that the Bot Service is acting as a type of relay between the Microsoft Teams Service and the underling Bot Application. We can make a reasonable assumption (key word assumption) that the Foundry Agent integration is working somewhat similar, but with some differences given the additional RBAC check and nature of their push button integration.
If we crack open a Bot Service resource Foundry creates automatically, we can get some insights into how the Bot Service is being configured.
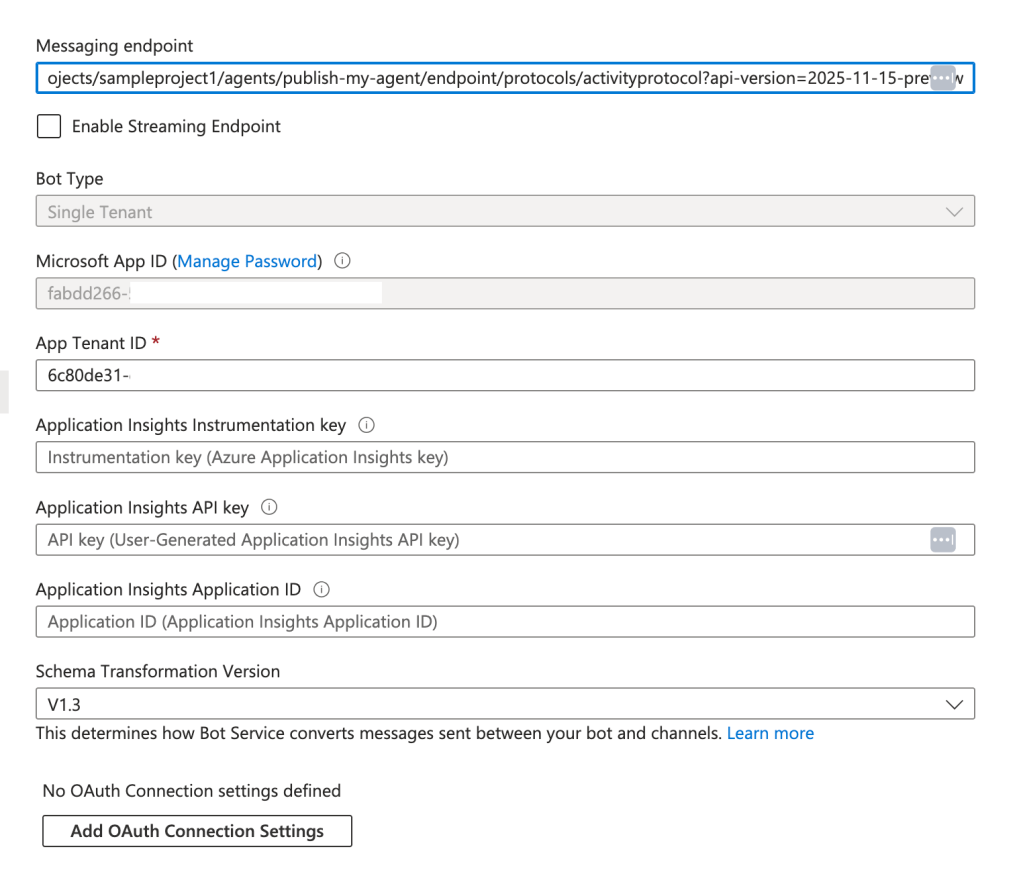
First we see that the messaging endpoint (the endpoint where the Bot Service Connector delivers messages it receives from Teams to) is the set in a format of https://FOUNDRY_ACCOUNT_NAME.services.ai.azure.com/api/projects/PROJECT_NAME/agents/AGENT_NAME/endpoint/protocols/activityprotocol?api-version=2025-11-15-preview. If we disable public network access and lock our Foundry resource behind a Private Endpoint, this URI would be unreachable by the Bot Service Connector. This creates the requirement I discussed earlier where we have to put some other infrastructure in front of those endpoint to make it available to the public IP world and mitigate the risks to do so (such as Graeme’s suggestions in his blog). Enabling Private Link for the Bot Service will not rid you of this requirement because that feature is centered around the use case of Direct Line which is more so used for custom built bots running in App Services (layman’s view) and only locks down the inbound access to the Bot Service. The integration with Teams requires the Bot Service stay public network access enabled, which means the traffic to the Bot App (agent) is going to come from the Microsoft public backbone driving this additional infrastructure requirement. This is where we’d modify the messaging endpoint to point to some other public IP-facing infra and route it to the Foundry Private Endpoint accordingly.
The next thing worth looking at is the Microsoft App ID. If we query this via the az cli with az ad sp show –id, we’ll see this maps to the Entra ID Agent Identity of the Foundry Agent. Anytime you create a Foundry Agent, an Entra ID Agent Identity Blueprint and Entra ID Agent Identity is provisioned inside of Entra ID. I plan on covering Entra ID Agent Identities in another post in the future, but for now think of them as a subclass of a service principal designed to cater to the security needs and ephemeral nature of agents. One of the best write-ups you can find online on this topic right now is from Christian Post. His series on the topic is worth a read.
By setting the Microsoft App ID to the agent’s Entra ID Agent Identity, we tie the bot service to the agent. We’ll see how this comes below.
Let’s take a look at a message coming from the Bot Service Connector into the agent. I captured this using an App Gateway + APIM pattern (similar to what is in Graeme’s post) and turned on request/response logging and captured all of the headers.
What we get is this:
[ { "headers": { "Authorization": { "type": "Bearer", "token": { "header": { "alg": "RS256", "kid": "SERixAMWrs46-gqrTrtMrkfbnuE", "x5t": "SERixAMWrs46-gqrTrtMrkfbnuE", "typ": "JWT" }, "payload": { "serviceurl": "https://smba.trafficmanager.net/amer/6c80de31-d5e4-4029-93e4-5a2b3c0e1299/", "nbf": 1778985043, "exp": 1778988643, "iss": "https://api.botframework.com", "aud": "a6790ff6-8752-4654-8ad8-4129842d1042" }, "signature": "hU7bOD-Awszt9zN07bwk7XtQ_E6hT1QGYgBQnDGxz75BF-QvO6gXBjCmo7FTjWizVXccen3mRi5xvSUIWO-vmrydJ9x5nSNaaVvIsHJm8T2agY3iOFDy_0Ii1t3uevJyiRqM_3T8Zi82T8P3umK6x3arkRbBzCWWQHJJs53pYm9m1lKyBax4jddjA3zBWltdcEtZixUEr9L73Qkoj4jU6d-QHyOxKAZnSJCaKzgAhtVOyQDMHU04PnPDNVKEQ5Efb2e5dx4Nqg2HoH1XQraa3zmE5_BGpIx1lIWPXA0oLaDLVnAhDEsS65H4mm48xCsR3l6VKgJc15pLPauTb5SoUw" } }, "Content-Length": "1098", "Content-Type": "application/json; charset=utf-8", "Host": "apim-example5ji.apim.XXXX.com", "Max-Forwards": "10", "User-Agent": "Microsoft-SkypeBotApi (Microsoft-BotFramework/3.0)", "X-AppGW-Trace-Id": "8ca4348bdd71a1c004935143c7cf7cb0", "X-ORIGINAL-HOST": "agent.XXXX.com", "x-ms-conversation-id": "a:1Xl9msHS_A_eeI1hPHlVR_8OIrMzE90dFdnC8eYmn8UyRlMA4-VaE-Z5omzp-U8cu-PyufpeI08o9sxtVj2S_Wq_beuvR8VGThDKyePyyll8UqG3Wg7ZMmI5OBsVZMWY8", "x-ms-tenant-id": "6c80de31-d5e4-4029-93e4-5a2b3c0e1299", "MS-CV": "6KZTHFyq5rFY/64p/ywW+A.1.1.1.1.1011601833.1.1", "X-FORWARDED-PROTO": "https", "X-FORWARDED-PORT": "443", "X-Forwarded-For": "52.112.116.120:15428;10.0.12.5", "X-Original-URL": "/foundry/api/projects/sampleproject1/agents/published-agent-1/endpoint/protocols/activityprotocol?api-version=2025-11-15-preview", "X-ARR-LOG-ID": "633dc336-3a11-4095-9540-d39a0cd99dc4", "CLIENT-IP": "[fd40:5f98:1f:9145:6e4f:200:a00:c05]:48814", "DISGUISED-HOST": "apim-example5ji.apim.XXXX.com", "X-SITE-DEPLOYMENT-ID": "apimwebappF7goUDzbkpZ1MlRL4Klo4uAVLlNNaKbE2UiIMOxN__d61e", "WAS-DEFAULT-HOSTNAME": "apimwebappf7goudzbkpz1mlrl4klo4uavllnnakbe2uiimoxn.azurewebsites.net", "X-MS-PRIVATELINK-ID": "520132703", "X-AppService-Proto": "https", "X-ARR-SSL": "4096|256|CN=R12;O=Let's Encrypt;C=US|CN=apim-example5ji.apim.XXXX.com", "X-Forwarded-TlsVersion": "1.3", "X-WAWS-Unencoded-URL": "/foundry/api/projects/sampleproject1/agents/published-agent-1/endpoint/protocols/activityprotocol?api-version=2025-11-15-preview", "X-Azure-JA4-Fingerprint": "t13d311100_e8f1e7e78f70_a11995863d32" }, "severity": "Information", "timestamp": "2026-05-17T02:30:43.8931561Z", "source": "request-headers" }]
In the above I decoded the JWT included in the authorization header. In the JWT we can see that it’s been issued by https://api.botframework.com which jives to Moim’s blog in that the Bot Service has its own STS (security token service) which is used to generate access tokens to authenticate downstream to the Bot. The serviceUrl tells the agent where to send the response it generates for the user’s question. You’ll see that my tenant id is appended to this URL. The audience in this case maps to the published-agent-1’s Entra ID Agent Identity. As Graeme recommends, you can craft a simple policy in APIM to validate this information to assure the access token is coming from a trusted tenant and is intended for the agent its being sent to.
We also have a header called x-ms-tenant-id (thanks to my peer Shaun Callighan for pointing this out to me) which could also be checked at the App Gateway (or similar L7 gateway) to do some degree of validation. Not as good as a JWT validation Graeme suggested, but it’s something if a full fledged API Gateway is too much for you.
Summing it up for now
Okay, my brain is fried and I’m sure yours is too so I’m going to save walking through the programmatic process for tomorrow. For that post I’ll focus less on the whats and whys and more so on how the hows. At this point you should have a reasonable good understanding of what this button actually does and why this button will not be an option for most enterprises. The few callouts I’ll make:
- The publish button in the Foundry Portal (today) requires the user to have Contributor or Owner on the resource group or subscription because it automatically deploys a Bot Service resource to the resource group the Foundry resource is in. Likely a no go from the start for most enterprises.
- The publish button in Foundry Portal (today) requires the Foundry resource have public network access enabled. Likely a no go from the start for most enterprises.
- Once the agent is published to teams, the users interacting with it require the Foundry User role in order to interact with the agent. If they don’t have it, they’ll get an authorization failure when trying to chat with the bot.
- When public network access is disabled for the Foundry resource, you’ll need to find a way to make that endpoint accessible using a public IP. You have lots of patterns available to you here. At layer 4, you should be able to lock down inbound traffic to Teams traffic at 52.112.0.0/14 and 52.122.0.0/15. If you’re ingressing via a firewall, it’s a simple firewall rule. If you’re ingressing from an Application Gateway you can use a WAF rule. Wait for this to be officially documented in the Microsoft public documentation.
In combination with the above, you should ideally go the route Graeme suggested and to incorporate some piece of infrastructure, such as APIM, that can do full validation of the JWT. Header validation of the x-ms-tenant-id is an option, but it’s not to the level of mitigation that full JWT validation is. Patterns for this include:
- APIM v2 configured for public inbound and regional vnet integration
- APIM classic configured for external mode
- App Gateway with a public listener with APIM v2 VNet Injected or PE + regional vnet integration behind it (my preference)
- App Gateway with a public listener with APIM classic VNet injection behind it (my preference)
- Firewall DNAT + APIM v2 VNet Injected or PE + regional vnet integration behind it
- Firewall DNAT + APIM classic VNet injection behind it
- There is an outbound flow from the Foundry Agent subnet (assuming you’re using Foundry Agents with VNet injection) that is sent to and endpoint at tenant.api.powerplatform.com (mine was il-6c80de31d5e4402993e45a2b3c0e12.99.tenant.api.powerplatform.com) where the 6c…….12.99 was my tenant id). I’m still trying to get clarity as to what this call is for. I’ll update this once I get it. I’d expect to see traffic to the endpoint in the serviceUrl but it looks like that traffic is flowing out the Microsoft side vs being tunneled into the customer virtual network even with Vnet injection (not uncommon for Foundry Agents w/ VNet injection).
- There is a programmatic way to do this without having to use the publish button which I’ll cover next post.
See you next post folks!


")

{kind=link}